解决微调大模型中文输出乱码问题 作者: lattice 时间: 2025-10-27 分类: 日常生活 评论 ## 引言 在使用Unsloth框架进行Qwen3模型的中文流式推理时,遇到了一个常见但棘手的问题:流式输出过程中出现Unicode替换字符(`�`)乱码。 ## 问题分析 ### UTF-8编码与BPE分词器的冲突 Qwen3模型使用BPE(Byte Pair Encoding)分词器,中文字符的token化有以下特点: - **多Token表示**:一个中文字符通常被分解为2-3个token - **UTF-8字节级分解**:中文字符的UTF-8编码(3字节)可能被拆分到不同的token中 - **边界不固定**:token边界不一定与字符边界对齐 **具体示例**: ```Text 字符: "珠江" UTF-8字节: [0xE7, 0x8F, 0xA0, 0xE6, 0xB1, 0x9F] # 每个字符3字节 Token序列: [珠_token1, 珠_token2, 江_token1, 江_token2] # 可能的分割方式 ``` ### 乱码产生的根本原因 在流式生成过程中,token是逐个或分批到达的: 1. **问题场景**: - 第1批tokens: [珠_token1, 珠_token2] # 不完整 - 第2批tokens: [江_token1, 江_token2] # 完整 2. **错误的处理方式**: - 如果token边界不对齐,可能出现不完整的字符解码 - 例如:只收到珠_token1时,解码结果可能是"�"(乱码) 3. **增量计算错误**: ```Text 第一次:last_content = "上午", new_content = "上午 + �", delta = " + �" 第二次:last_content = "上午 + �", new_content = "上午 + 珠江", delta = "江" 客户端拼接:"+ �" + "江" = "+ �江" ``` ### GPT-2字节映射机制分析 Qwen tokenizer继承了GPT-2的字节到Unicode映射机制。这个机制的设计目的是为了处理所有可能的字节值(0-255),将它们映射到可打印的Unicode字符上。 ```python def bytes_to_unicode(): bs = ( list(range(ord("!"), ord("~") + 1)) + # 可打印ASCII字符 list(range(ord("¡"), ord("¬") + 1)) + # 扩展拉丁字符 list(range(ord("®"), ord("ÿ") + 1)) # 更多扩展字符 ) cs = bs.copy() n = 0 for b in range(2**8): # 遍历所有256个字节值 if b not in bs: bs.append(b) cs.append(2**8 + n) # 为未映射的字节分配新的Unicode码点 n += 1 cs = [chr(code) for code in cs] return dict(zip(bs, cs)) ``` 这个映射机制的核心思想是:将每个字节值(0-255)映射到一个唯一的Unicode字符,确保所有可能的字节序列都能被表示为Unicode字符串。 ### 乱码产生的根本原因 #### 1. 跨token编码问题 在流式生成过程中,token是逐个或分批到达的: **问题场景**: - 第1批tokens: [珠_token1, 珠_token2] # 不完整 - 第2批tokens: [江_token1, 江_token2] # 完整 **错误的处理方式**: - 如果token边界不对齐,可能出现不完整的字符解码 - 例如:只收到珠_token1时,解码结果可能是"�"(乱码) #### 2. GPT-2映射错误 乱码的产生是一个复杂的过程,涉及多个环节: 1. **跨token编码问题**: 中文字符被分割成多个token - 当模型生成中文字符时,tokenizer会将一个中文字符分割成多个token - 例如,中文字符"咖"可能被分割成4个token:`Ġ`、`å`、`Ĵ`、`ĸ` 2. **映射错误**: GPT-2映射将UTF-8字节映射到非标准Unicode字符 - 每个token对应一个特定的Unicode字符 - 这些字符不是标准的中文字符,而是GPT-2映射产生的特殊字符 3. **解码失败**: 标准tokenizer.decode()无法正确处理这些映射 - 当这些特殊字符被直接输出时,就形成了乱码 - 用户看到的是`ĠåĴĸ`而不是"咖" #### 3. 增量计算错误 SSE(Server-Sent Events)服务通过计算增量来发送新内容: **错误的增量计算逻辑**: - 服务端维护上次发送的内容:`last_content` - 计算增量:`delta = new_content[len(last_content):]` - 发送增量给客户端 **问题场景**: - 第一次:`last_content = "上午"`,`new_content = "上午 + �"`,`delta = " + �"` - 第二次:`last_content = "上午 + �"`,`new_content = "上午 + 珠江"`,`delta = "江"` - 客户端拼接:`" + �" + "江" = " + �江"` ### 乱码字符类型分析 #### 1. 中文字符乱码 通过深入分析,我们发现了乱码字符与正确中文字符之间的对应关系: | 乱码字符 | 字节值 | 正确解码结果 | 说明 | |---------|--------|-------------|------| | `ĠåĴĸ` | [32, 229, 146, 150] | ` 咖` | 中文字符"咖"被分割成4个token | | `Ġ西` | [32, 232, 165, 191] | ` 西` | 中文字符"西"被分割成4个token | | `ĠçĥŃ` | [32, 231, 131, 173] | ` 热` | 中文字符"热"被分割成4个token | | `Ġè¡Ĺ` | [32, 232, 161, 151] | ` 街` | 中文字符"街"被分割成4个token | | `ĠèĮ¶` | [32, 232, 140, 182] | ` 茶` | 中文字符"茶"被分割成4个token | 从这些例子可以看出,每个中文字符都被分割成4个token,其中第一个token通常是`Ġ`(对应字节值32,即空格字符),后面3个token对应中文字符的UTF-8字节序列。 #### 2. 拉丁字符乱码 除了中文字符乱码,我们还发现了另一种乱码模式:**拉丁字符乱码**。这种乱码的特点是扩展拉丁字符与中文字符混合出现: | 乱码字符 | 正确解码结果 | 说明 | |---------|-------------|------| | `¤IJ厅` | `餐厅` | 扩展拉丁字符`¤IJ`与中文字符`厅`混合 | | `«闪店` | `网红店` | 扩展拉丁字符`«`与中文字符`闪店`混合 | | `±展` | `展览` | 扩展拉丁字符`±`与中文字符`展`混合 | **拉丁字符乱码的特征分析:** - **Unicode范围**: 扩展拉丁字符位于U+00A0 - U+017F范围 - **混合模式**: 扩展拉丁字符 + 中文字符的组合 - **字符长度**: 拉丁字符部分通常为1-2个字符 - **上下文依赖**: 需要结合中文字符的上下文来推断完整词汇 ## 解决方案 ### 核心思路 我们的解决方案基于以下核心思路: - **批量解码优先**: 首先尝试tokenizer的批量解码功能 - 利用tokenizer自身的批量解码能力,这通常能处理大部分跨token编码问题 - 这是最高效的方法,因为不需要额外的处理步骤 - **逐token修复**: 如果批量解码失败,则逐个token进行修复 - 当批量解码仍然产生乱码时,我们需要深入每个token进行修复 - 这确保了即使是最复杂的情况也能得到处理 - **GPT-2反向映射**: 使用GPT-2字节映射的逆向过程 - 将乱码字符转换回原始的字节值 - 这是修复过程的关键步骤 - **UTF-8重新解码**: 将字节值重新解码为正确的UTF-8字符 - 将字节值重新组合成正确的UTF-8字节序列 - 最终解码为可读的中文字符 - **拉丁字符乱码修复**: 针对拉丁字符乱码的特殊处理 - 检测扩展拉丁字符与中文字符的混合模式 - 基于上下文和模式识别进行智能修复 - 避免硬编码,使用通用规则进行推断 ### 1. Token缓冲机制 **核心思想**: 不立即解码每个token批次,而是累积所有tokens后进行整体解码。 **实现原理**: - 维护一个token缓冲区,累积所有到达的tokens - 每次收到新tokens时,将其添加到缓冲区 - 对完整的token序列进行整体解码 - 这样可以确保解码时总是有完整的字符信息 **核心代码实现**: ```python class CustomTextStreamer: def __init__(self, tokenizer, queue_manager, task_id, user_message: str = "", enable_thinking: bool = False): self.tokenizer = tokenizer self.queue_manager = queue_manager self.task_id = task_id # 使用token缓冲避免UTF-8多字节被拆分 self._token_buffer = [] # 累计的token ids self._last_decoded_text = "" # 上一次整体解码结果 self.response_text = "" # 清洗后的当前轮累计 self.first_token_time = None ``` ### 2. UTF-8边界检测 **关键功能**:确保输出的文本总是在完整的UTF-8字符边界结束。 **算法实现**: ```python def ensure_utf8_boundary(text: str) -> str: """确保字符串在UTF-8字符边界处截断,避免不完整字符""" if not text: return text try: utf8_bytes = text.encode('utf-8') except UnicodeEncodeError: return text # 从末尾向前扫描,找到最后一个完整的UTF-8字符边界 i = len(utf8_bytes) while i > 0: try: return utf8_bytes[:i].decode('utf-8') except UnicodeDecodeError: i -= 1 return "" ``` ### 3. 安全的增量计算 **处理流程**: 1. 累积tokens到缓冲区 2. 整体解码token序列 3. 应用UTF-8边界检测 4. 计算与上次安全文本的差异 5. 发送安全的新增量内容 **核心实现**: ```python def put(self, value): """TextStreamer的回调方法:累计token整体解码,避免UTF-8断裂导致的乱码""" try: # 累计tokens if isinstance(value, torch.Tensor): if value.dim() > 1: value = value.flatten() token_ids = value.tolist() if isinstance(token_ids, int): token_ids = [token_ids] self._token_buffer.extend(token_ids) else: return # 跳过无效值 # 整体解码并生成清洗后的累计 decoded_total = self.tokenizer.decode(self._token_buffer, skip_special_tokens=True) # 确保UTF-8边界完整,避免不完整字符(被截断) decoded_total = ensure_utf8_boundary(decoded_total) self._last_decoded_text = decoded_total current_round = self._extract_current_round(decoded_total) cleaned = self._post_clean(current_round) self.response_text = cleaned # 实时更新Redis中的流式结果 if self.queue_manager and self.response_text: self.queue_manager.update_stream_result(self.task_id, self.response_text) except Exception as e: logger.error(f"TextStreamer put方法错误: {e}") ``` ### 4. 乱码检测和修复机制 #### 4.1 乱码检测 正则判断特殊符号或者乱码 #### 4.2 单token修复函数 直接使用vocab.json(大模型语法表)解码token,避免tokenizer的乱码问题 #### 4.3 拉丁字符乱码修复 基于模式识别的拉丁字符乱码修复 ## 技术实现 ### 框架集成 解决方案完全兼容Transformers的TextStreamer接口,与Unsloth框架无缝集成: ```python # 创建自定义streamer custom_streamer = CustomTextStreamer(tokenizer, queue_manager, request.task_id, user_message=request.message, enable_thinking=request.enable_thinking) # 使用TextStreamer进行流式生成 outputs = model.generate( **inputs, max_new_tokens=request.max_tokens, temperature=request.temperature, top_p=request.top_p, top_k=request.top_k, do_sample=True, pad_token_id=tokenizer.eos_token_id, streamer=custom_streamer, # 使用自定义TextStreamer return_dict_in_generate=True, output_scores=False, ) ``` ## 实验结果 ### 问题解决效果 **修改前**: ``` 流式输出: "上午 + �江" 最终结果: "上午 + 珠江" ``` **修改后**: ``` 流式输出: "上午 + " → "上午 + 珠" → "上午 + 珠江" 最终结果: "上午 + 珠江" ``` ## 经验总结 ### 关键发现 通过深入分析和测试,我们发现了以下关键点: 1. **跨token编码问题**: 大部分乱码都是因为中文字符被分割成多个token导致的 - 一个中文字符通常被分割成4个token - 第一个token通常是`Ġ`(对应空格字符) - 后面3个token对应中文字符的UTF-8字节序列 2. **批量解码有效**: 使用tokenizer的批量解码功能可以自动处理跨token的编码问题 - 这是最高效的修复方法 - 能处理大部分常见情况 - 应该优先使用 3. **修复范围广泛**: 不仅限于中文字符,还包括emoji等特殊字符 - 解决方案具有通用性 - 可以处理各种多字节字符 - 适用范围广 4. **模式识别**: 乱码token通常与特定的后续token组合才能正确解码 - 需要将多个token组合起来才能正确解码 - 单独处理每个token可能无法得到正确结果 5. **拉丁字符乱码**: 发现了新的乱码模式:扩展拉丁字符与中文字符的混合 - 扩展拉丁字符位于U+00A0 - U+017F范围 - 需要基于上下文进行智能推断 - 避免硬编码,使用通用规则处理 ### 技术要点 在实现解决方案的过程中,我们掌握了以下技术要点: 1. **GPT-2映射理解**: 深入理解GPT-2的字节到Unicode映射机制 - 映射表的结构和生成方式 - 反向映射的实现方法 - 字节值的处理策略 2. **UTF-8编码原理**: 掌握UTF-8多字节字符的编码规则 - 中文字符的UTF-8编码方式 - 字节序列的组合和解码 - 错误处理机制 3. **渐进式修复**: 优先使用简单方法,复杂情况使用深度修复 - 批量解码优先 - 逐token修复作为备选 - 回退机制保证稳定性 4. **有效性验证**: 确保修复结果的正确性 - 中文字符检测 - 有效字符验证 - 质量保证机制 5. **拉丁字符乱码处理**: 掌握拉丁字符乱码的处理方法 - 正则表达式模式识别 - 上下文推断算法 - 智能替换策略 ## 兼容性测试 - **模型兼容**:适用于Qwen3及其他BPE分词器模型 - **语言支持**:支持中文、英文等多语言输出 - **框架兼容**:完全兼容Unsloth和Transformers框架 ## 适用场景 - **中文大模型推理**:特别适用于中文等多字节字符的处理 - **流式输出场景**:适用于需要实时显示生成过程的场景 - **多语言支持**:适用于需要处理多种语言的应用 - **生产环境部署**:适用于高并发、高可用的生产环境
一些关于服务器的问题 作者: lattice 时间: 2019-05-05 分类: 生活日记,日常生活 评论 ## 感动中国 本站服务器已经从香港idc迁到了腾讯云的广州服务器 毕竟离自家近且对海外出口速度应该快一些吧...?? ## 关于配置与价格 一开始我使用的是香港idc,只花了29元抢的神机(续费也是29...) 后期升级配置变成了个人博客的服务器,价格也直接飙到了 57/Month 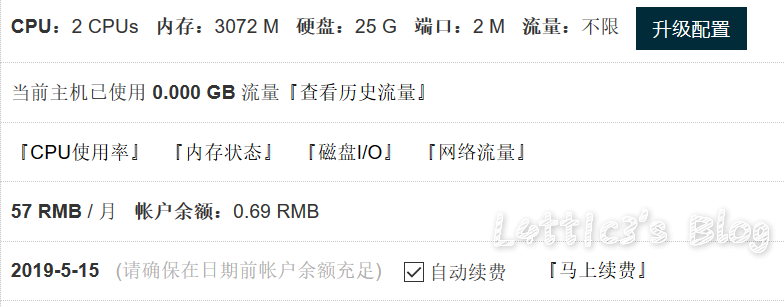 抛弃这台服务器真的太心疼了...因为不限流,用来做ssr真的完美 但是个人预算顶不顺...哭 所以就直接入手了腾讯云的学生机(感谢Adrian给的建议) 学生机的配置就是默认配置,想升级结果发现血妈贵.... 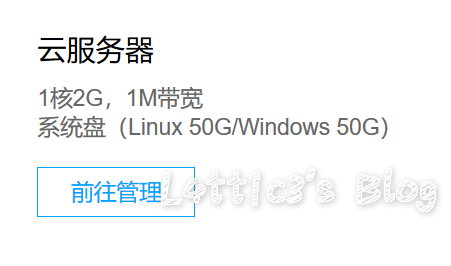 价格是我直接怼上了120/Year,其实还可以吧.. 但是服务器配置还是不能心满意足,后期很多东西可能需要在阿里云的学生机上搭 阿里云跟腾讯云的学生机价格差不了多少,不贵 ## 关于对象存储 Emmm对象存储这个的话... 之前买了个一年阿里的oss,好像才16块钱?? 反正很便宜,然后购买腾讯云的学生机也送了六个月50G的cos存储(安利腾讯云) 所以每周服务器都会备份到阿里oss和腾讯cos 但是typecho的图片对象存储还没特别完善,插件很多都get不到图片和自带水印,所以文章内所上传的所有图片还是暂存主机 ## 关于域名 现在域名还是使用 https://www.latticehub.xyz/ 因为原本服务器使用的域名是https://www.shadowlink.top/ 还存在一定的流量,所以https://www.shadowlink.top/ 这个域名使用了反向代理到了现在所使用的域名(虽然可能存在了ssl证书的问题...主域名没出现就行) 后期再考虑换成个人博客的域名,现暂使用原团队网站域名 ## 安全问题 CDN用的是连我自己都讨厌的Cloudflare 迁移之后暂时还没全面完善和检查 如果发现问题可以直接找我来上报,发现了全部有奖励 (有是有,但是没多少,范围就Under 30吧) 网站程序方面问题不接收 因为是typecho官方问题我不能处理,所以只收针对服务器配置的安全问题 任何问题可以直接微信联系我  ## 写给圈子里的朋友 可以对网站进行测试与漏洞挖掘 但是本人不接受任何端口爆破和压力测试等攻击性测试 如发现,爆菊处理 ## 写给其他博客的访客 这个博客具有极强包容性也欢迎各位的访问 希望技术贴能让你们学到东西 怼人贴能让你们看清更多事实 **我是Lattice,拜你个拜**
cxk真的进攻B站变成iKuniKun站啦??(吃瓜篇+主要信息定位) 作者: lattice 时间: 2019-04-22 分类: 网络安全,日常生活 评论 ## 开头 一早起来就被朋友圈刷爆了... 全都是b站的后端源码泄露的事情 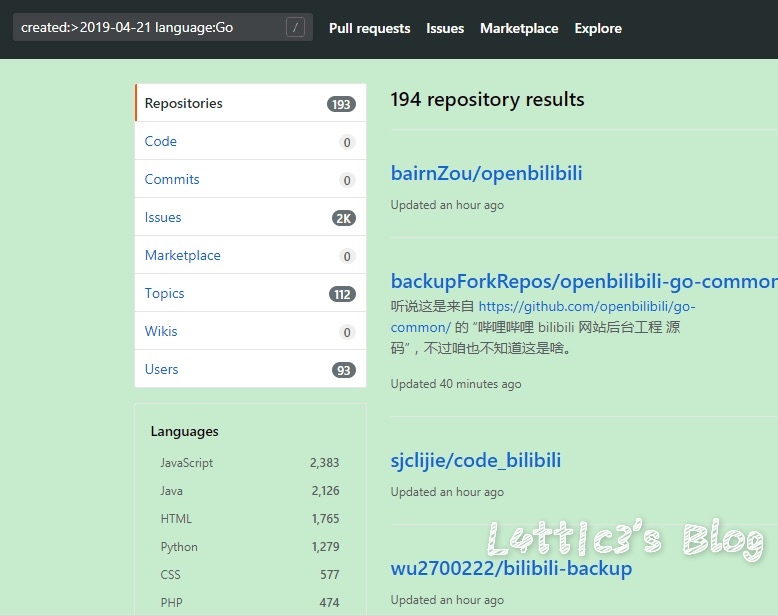 B站应急响应还是蛮快的,项目很快就删除了 但是还是有大佬fork了...我就顺便下载了两个项目下来看看具体泄露了啥 这里就不提供下载链接了,找找就有了 ## 分析 ok,到现在我一共发现了三个版本的源码 版本1和2中间就相差了0.3MB 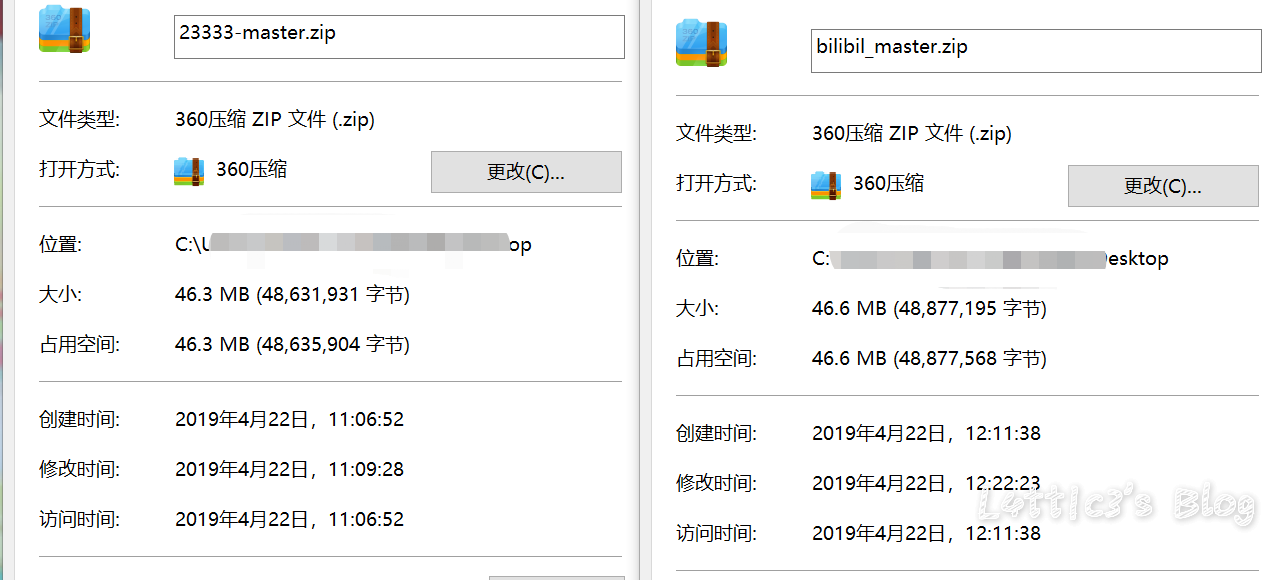 2Real 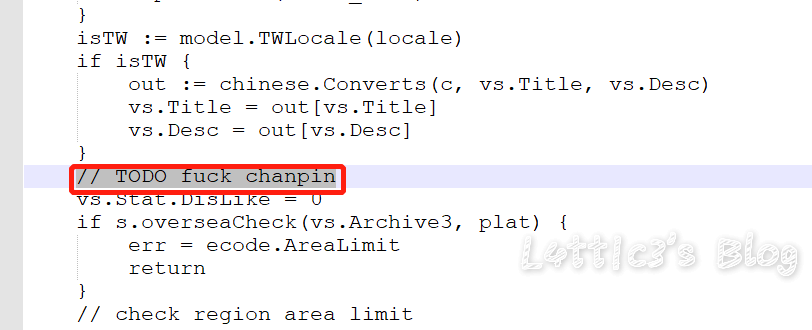 后面我还看到了一个版本3,其大小高达100MB+ 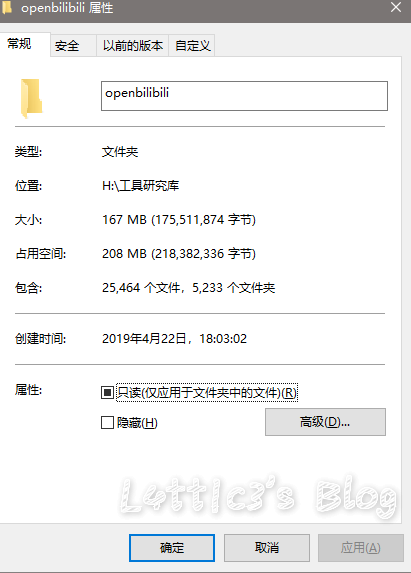 抛开版本3(太大了...懒得一个个翻) 看回版本1和版本2的源码 中间主要相差得就是一个文件 ``` app\admin\main\laser\cmd\laser-interface.toml ``` 也就是网上盛传的一个域名mail的数据 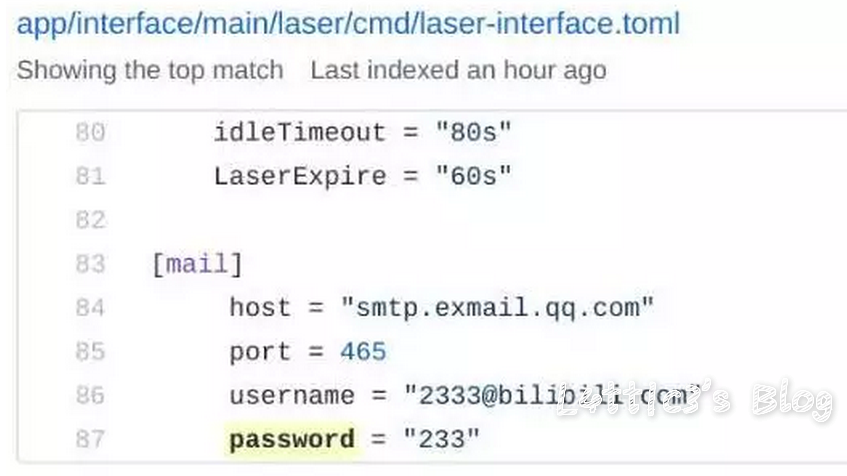 其他的东西,几个版本的源码中的信息几乎相似,主要的东西还在那里 下面是翻出的部分数据截图(因为网上已经传开了..): email泄露:  tcptest连接信息: 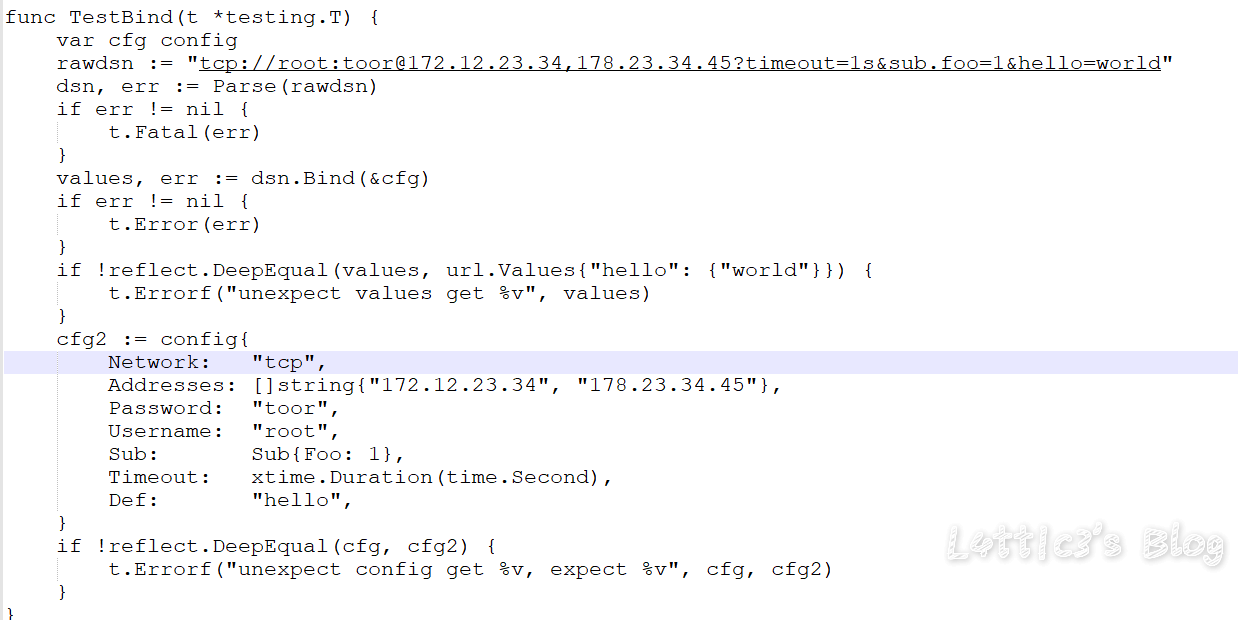 下面.co的链接都是内网环境,看看就行 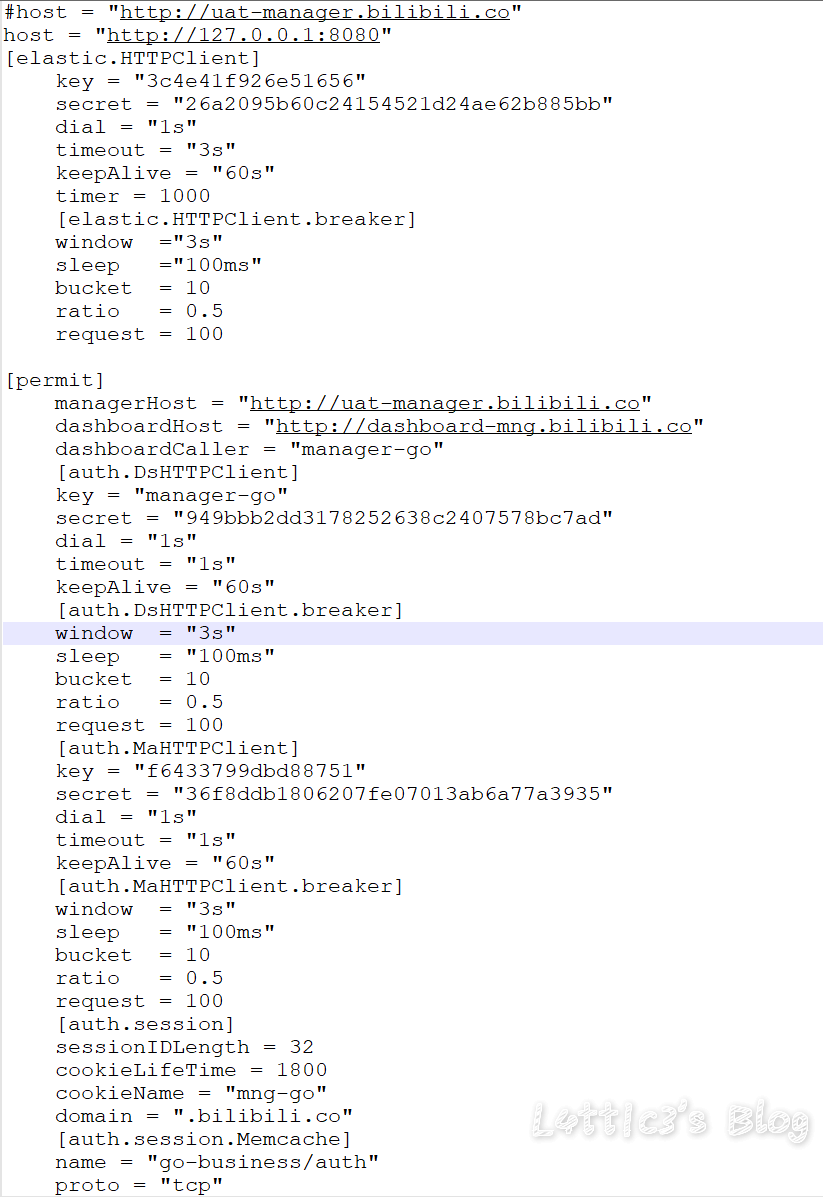  版本1中(app\admin\main\laser\cmd\laser-admin.toml)跟版本2中的(app\admin\main\laser\cmd\laser-interface.toml)的数据区别:  就是单纯的域名邮箱被删除了且密码以及更改(吃瓜就行) 然后大概就是这些 ## 主要信息定位 好多小伙伴说..这信息在源码哪个位置看到的?? 这里提供一个主要信息的定位: ``` app\admin\main app\admin\main\laser\cmd(爆出邮箱的那个文件夹) app\interface\main app\interface\main\passport-login library\database ``` ## 结尾 但是还是感谢B站的无私开源  引用一句话: 我都不慌,你们慌什么(毛剑,Bilibili技术总监) 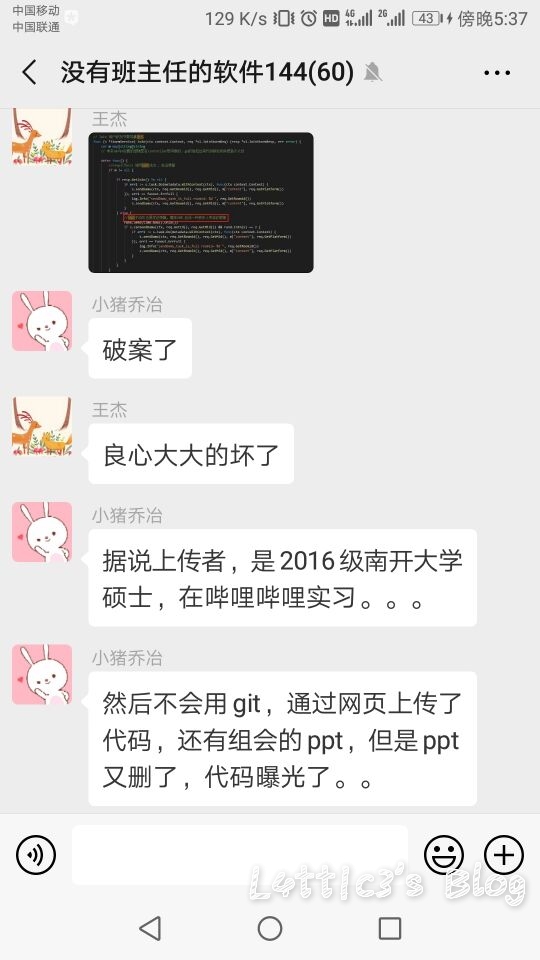
【跳车篇】这个傻逼宿舍...我要气死了 作者: lattice 时间: 2019-03-05 分类: 生活日记,日常生活 评论 ## 到底是跳哪一篇的车呢? 别说了,就是上一篇的 [【预告】在宿舍装路由器并刷回国酸S酸S乳R过程记录](https://www.latticehub.xyz/archives/64.html "【预告】在宿舍装路由器并刷回国酸S酸S乳R过程记录") ## 为啥呢?? MMP我整套东西都搭好了,结果路由器一直连不上网 然后我就上了宿舍这边的网络提供商网站上面一看 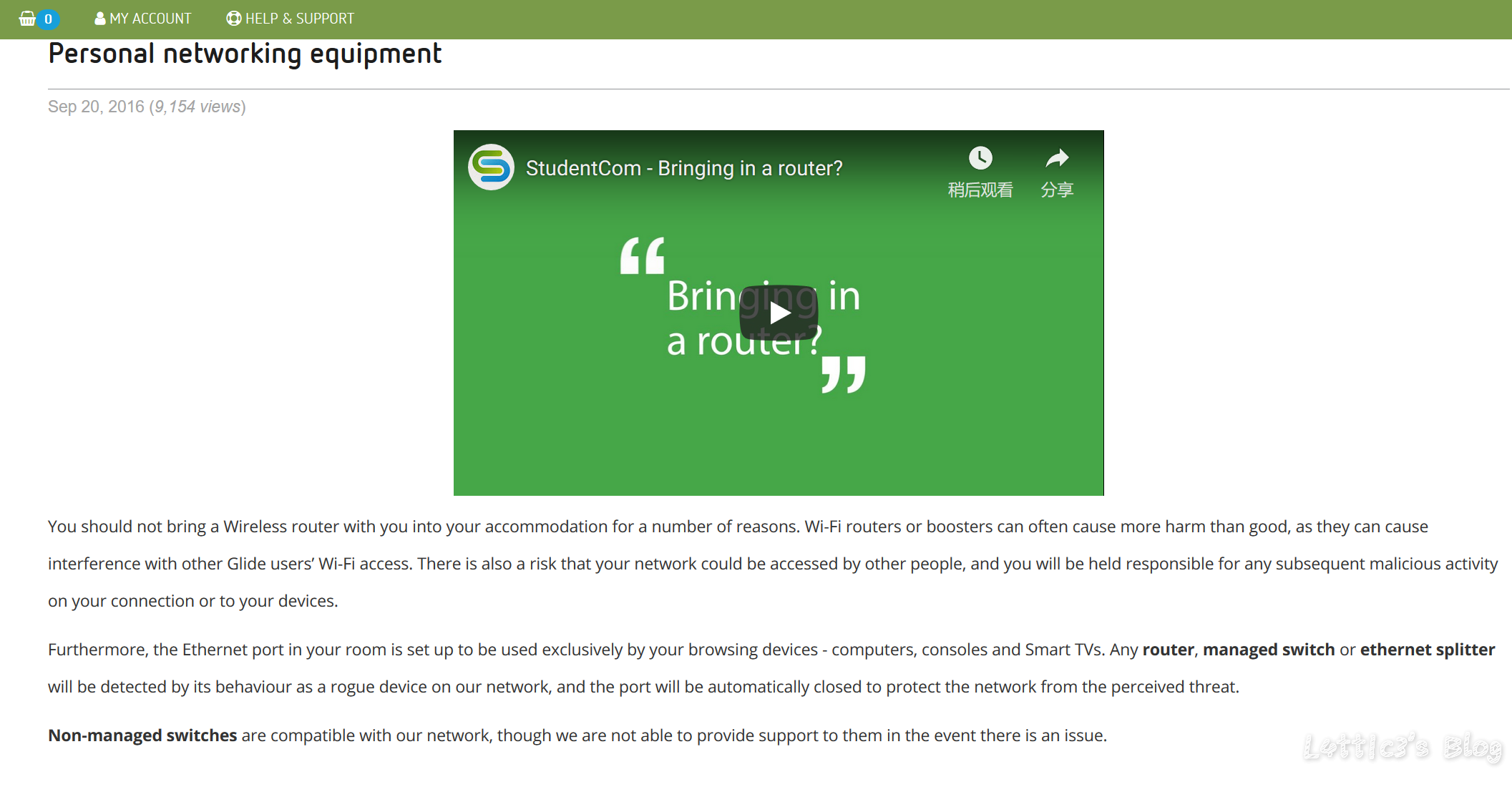 直接不给装路由器了都...接上了就直接屏蔽端口..我能有什么办法 实在没办法...全拆下来了 那我就给大家提供之前我说的宿舍回国和家庭酸S酸S乳R具体的走线图吧(哭) ## 路由器具体怎么刷呢(固件、开发版、酸S酸S乳R) 欸嘿嘿,为了锁定流量,我决定留到不知道多久之后的那一边博客再写(我懒) ## 宿舍方案 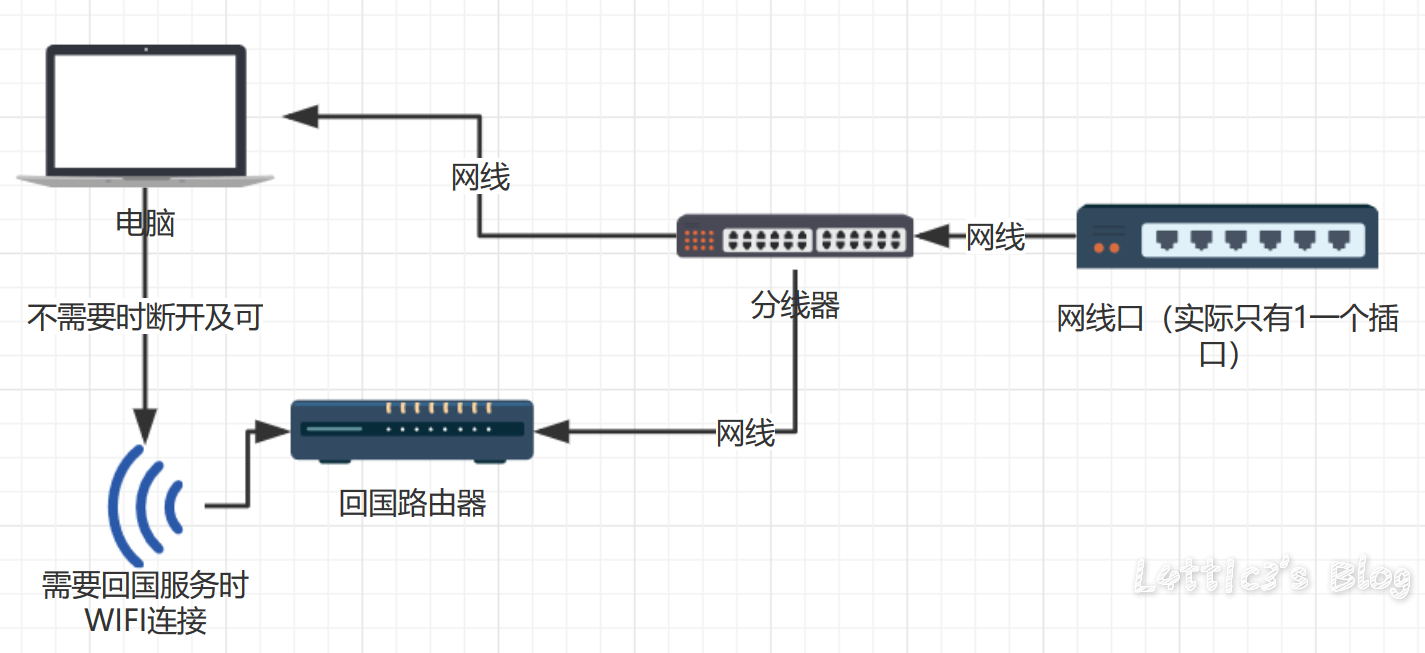 准确来说,弟弟我的方案是肯定行得通的,结果宿舍方爸爸这样弄我也没办法,被弄成弟弟(具体为啥看上面) ## 家庭方案 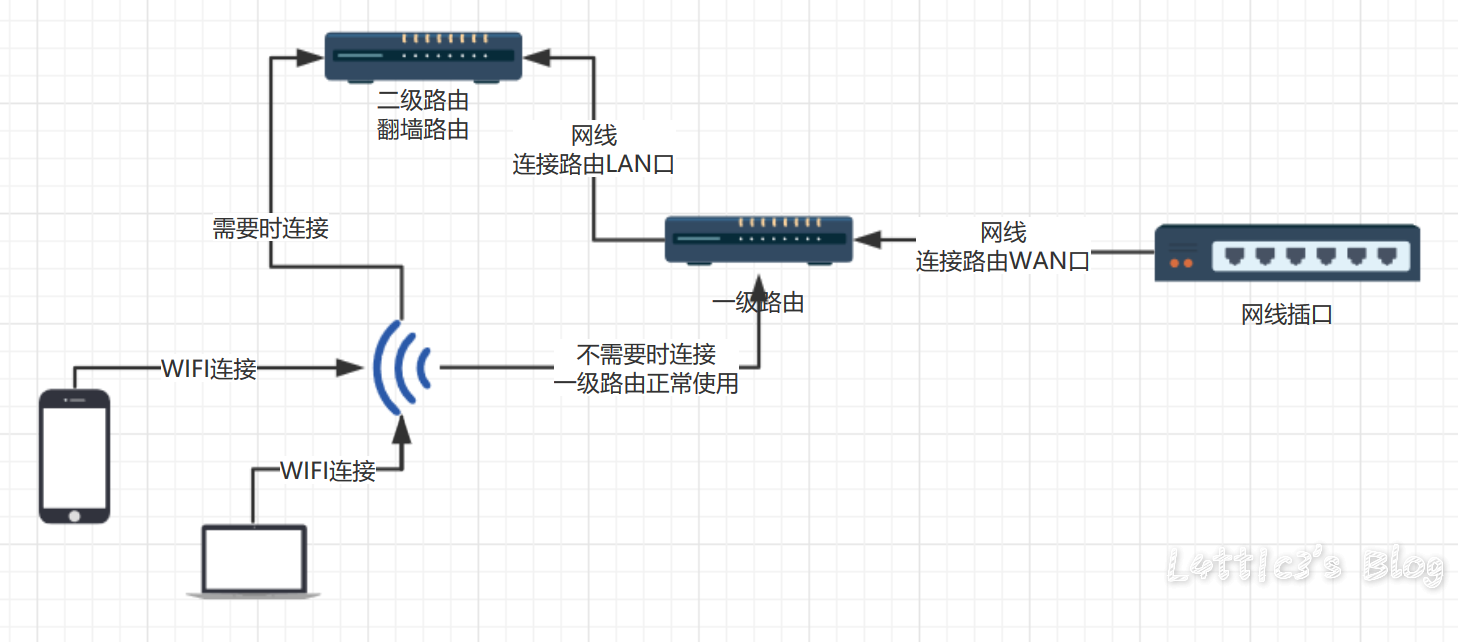 这个方案适用于国内小伙伴家里的家庭酸S酸S乳R看外面网站的需求,所有设备可以直接WIFI连接,台式机如果使用网线,可以网线插一级路由再买个usb的WIFI接收器(几十RMB..不会多于50RMB的),有需要时直接连接二级路由看外面网站就行 ## 最后!! **该方案适用于手机以及电脑wifi连接回国** 有什么问题随时可以在下方留言!! 熟人直接wechat找我也可以!!
【预告】在宿舍装路由器并刷回国酸S酸S乳R过程记录 作者: lattice 时间: 2019-02-26 分类: 生活日记,日常生活 评论 上周换了宿舍,结果房间里面只有一个网线的插口(气死) 在amazon uk找了一圈网线分线器都没有看到合适的 一上狗东就找到了合适的一款绿联的分线器(不打广告) 然后就买了一堆网线和分线器,因为...amazon uk的东西真的太贵了,大天朝还是牛逼啊 因为英国这边没法用网易云还有看各种什么xxx视频软件,所以顺便要家里寄过来一个之前自己刷过开发者和工具包的小米路由器2A(usb版)过来 经历了一个周末,今天终于到了  过几天有空了会把这WiFi设备搭起来 顺便给大家记录下来如何给小米路由器2A(usb版)刷开发者模式加固件 如果到时各位小伙伴不懂的话... 我还会画一张在自己宿舍里面搭路由器具体线路的走线图 (顺便再提供一张在国内家里如何使用双路由实现国内、翻墙的走线图给大家参考) **预计成本: (以下为国内价格,国外的话翻一倍就行,求别来跟我杠) 国内服务器:50元/月 路由器:我忘了,反正我爸买的,自己没花钱233333 网线:5.9元(0.5米长)+7.9元(1米长) 分线器:39元(两个) **