解决微调大模型中文输出乱码问题 作者: lattice 时间: 2025-10-27 分类: 日常生活 评论 ## 引言 在使用Unsloth框架进行Qwen3模型的中文流式推理时,遇到了一个常见但棘手的问题:流式输出过程中出现Unicode替换字符(`�`)乱码。 ## 问题分析 ### UTF-8编码与BPE分词器的冲突 Qwen3模型使用BPE(Byte Pair Encoding)分词器,中文字符的token化有以下特点: - **多Token表示**:一个中文字符通常被分解为2-3个token - **UTF-8字节级分解**:中文字符的UTF-8编码(3字节)可能被拆分到不同的token中 - **边界不固定**:token边界不一定与字符边界对齐 **具体示例**: ```Text 字符: "珠江" UTF-8字节: [0xE7, 0x8F, 0xA0, 0xE6, 0xB1, 0x9F] # 每个字符3字节 Token序列: [珠_token1, 珠_token2, 江_token1, 江_token2] # 可能的分割方式 ``` ### 乱码产生的根本原因 在流式生成过程中,token是逐个或分批到达的: 1. **问题场景**: - 第1批tokens: [珠_token1, 珠_token2] # 不完整 - 第2批tokens: [江_token1, 江_token2] # 完整 2. **错误的处理方式**: - 如果token边界不对齐,可能出现不完整的字符解码 - 例如:只收到珠_token1时,解码结果可能是"�"(乱码) 3. **增量计算错误**: ```Text 第一次:last_content = "上午", new_content = "上午 + �", delta = " + �" 第二次:last_content = "上午 + �", new_content = "上午 + 珠江", delta = "江" 客户端拼接:"+ �" + "江" = "+ �江" ``` ### GPT-2字节映射机制分析 Qwen tokenizer继承了GPT-2的字节到Unicode映射机制。这个机制的设计目的是为了处理所有可能的字节值(0-255),将它们映射到可打印的Unicode字符上。 ```python def bytes_to_unicode(): bs = ( list(range(ord("!"), ord("~") + 1)) + # 可打印ASCII字符 list(range(ord("¡"), ord("¬") + 1)) + # 扩展拉丁字符 list(range(ord("®"), ord("ÿ") + 1)) # 更多扩展字符 ) cs = bs.copy() n = 0 for b in range(2**8): # 遍历所有256个字节值 if b not in bs: bs.append(b) cs.append(2**8 + n) # 为未映射的字节分配新的Unicode码点 n += 1 cs = [chr(code) for code in cs] return dict(zip(bs, cs)) ``` 这个映射机制的核心思想是:将每个字节值(0-255)映射到一个唯一的Unicode字符,确保所有可能的字节序列都能被表示为Unicode字符串。 ### 乱码产生的根本原因 #### 1. 跨token编码问题 在流式生成过程中,token是逐个或分批到达的: **问题场景**: - 第1批tokens: [珠_token1, 珠_token2] # 不完整 - 第2批tokens: [江_token1, 江_token2] # 完整 **错误的处理方式**: - 如果token边界不对齐,可能出现不完整的字符解码 - 例如:只收到珠_token1时,解码结果可能是"�"(乱码) #### 2. GPT-2映射错误 乱码的产生是一个复杂的过程,涉及多个环节: 1. **跨token编码问题**: 中文字符被分割成多个token - 当模型生成中文字符时,tokenizer会将一个中文字符分割成多个token - 例如,中文字符"咖"可能被分割成4个token:`Ġ`、`å`、`Ĵ`、`ĸ` 2. **映射错误**: GPT-2映射将UTF-8字节映射到非标准Unicode字符 - 每个token对应一个特定的Unicode字符 - 这些字符不是标准的中文字符,而是GPT-2映射产生的特殊字符 3. **解码失败**: 标准tokenizer.decode()无法正确处理这些映射 - 当这些特殊字符被直接输出时,就形成了乱码 - 用户看到的是`ĠåĴĸ`而不是"咖" #### 3. 增量计算错误 SSE(Server-Sent Events)服务通过计算增量来发送新内容: **错误的增量计算逻辑**: - 服务端维护上次发送的内容:`last_content` - 计算增量:`delta = new_content[len(last_content):]` - 发送增量给客户端 **问题场景**: - 第一次:`last_content = "上午"`,`new_content = "上午 + �"`,`delta = " + �"` - 第二次:`last_content = "上午 + �"`,`new_content = "上午 + 珠江"`,`delta = "江"` - 客户端拼接:`" + �" + "江" = " + �江"` ### 乱码字符类型分析 #### 1. 中文字符乱码 通过深入分析,我们发现了乱码字符与正确中文字符之间的对应关系: | 乱码字符 | 字节值 | 正确解码结果 | 说明 | |---------|--------|-------------|------| | `ĠåĴĸ` | [32, 229, 146, 150] | ` 咖` | 中文字符"咖"被分割成4个token | | `Ġ西` | [32, 232, 165, 191] | ` 西` | 中文字符"西"被分割成4个token | | `ĠçĥŃ` | [32, 231, 131, 173] | ` 热` | 中文字符"热"被分割成4个token | | `Ġè¡Ĺ` | [32, 232, 161, 151] | ` 街` | 中文字符"街"被分割成4个token | | `ĠèĮ¶` | [32, 232, 140, 182] | ` 茶` | 中文字符"茶"被分割成4个token | 从这些例子可以看出,每个中文字符都被分割成4个token,其中第一个token通常是`Ġ`(对应字节值32,即空格字符),后面3个token对应中文字符的UTF-8字节序列。 #### 2. 拉丁字符乱码 除了中文字符乱码,我们还发现了另一种乱码模式:**拉丁字符乱码**。这种乱码的特点是扩展拉丁字符与中文字符混合出现: | 乱码字符 | 正确解码结果 | 说明 | |---------|-------------|------| | `¤IJ厅` | `餐厅` | 扩展拉丁字符`¤IJ`与中文字符`厅`混合 | | `«闪店` | `网红店` | 扩展拉丁字符`«`与中文字符`闪店`混合 | | `±展` | `展览` | 扩展拉丁字符`±`与中文字符`展`混合 | **拉丁字符乱码的特征分析:** - **Unicode范围**: 扩展拉丁字符位于U+00A0 - U+017F范围 - **混合模式**: 扩展拉丁字符 + 中文字符的组合 - **字符长度**: 拉丁字符部分通常为1-2个字符 - **上下文依赖**: 需要结合中文字符的上下文来推断完整词汇 ## 解决方案 ### 核心思路 我们的解决方案基于以下核心思路: - **批量解码优先**: 首先尝试tokenizer的批量解码功能 - 利用tokenizer自身的批量解码能力,这通常能处理大部分跨token编码问题 - 这是最高效的方法,因为不需要额外的处理步骤 - **逐token修复**: 如果批量解码失败,则逐个token进行修复 - 当批量解码仍然产生乱码时,我们需要深入每个token进行修复 - 这确保了即使是最复杂的情况也能得到处理 - **GPT-2反向映射**: 使用GPT-2字节映射的逆向过程 - 将乱码字符转换回原始的字节值 - 这是修复过程的关键步骤 - **UTF-8重新解码**: 将字节值重新解码为正确的UTF-8字符 - 将字节值重新组合成正确的UTF-8字节序列 - 最终解码为可读的中文字符 - **拉丁字符乱码修复**: 针对拉丁字符乱码的特殊处理 - 检测扩展拉丁字符与中文字符的混合模式 - 基于上下文和模式识别进行智能修复 - 避免硬编码,使用通用规则进行推断 ### 1. Token缓冲机制 **核心思想**: 不立即解码每个token批次,而是累积所有tokens后进行整体解码。 **实现原理**: - 维护一个token缓冲区,累积所有到达的tokens - 每次收到新tokens时,将其添加到缓冲区 - 对完整的token序列进行整体解码 - 这样可以确保解码时总是有完整的字符信息 **核心代码实现**: ```python class CustomTextStreamer: def __init__(self, tokenizer, queue_manager, task_id, user_message: str = "", enable_thinking: bool = False): self.tokenizer = tokenizer self.queue_manager = queue_manager self.task_id = task_id # 使用token缓冲避免UTF-8多字节被拆分 self._token_buffer = [] # 累计的token ids self._last_decoded_text = "" # 上一次整体解码结果 self.response_text = "" # 清洗后的当前轮累计 self.first_token_time = None ``` ### 2. UTF-8边界检测 **关键功能**:确保输出的文本总是在完整的UTF-8字符边界结束。 **算法实现**: ```python def ensure_utf8_boundary(text: str) -> str: """确保字符串在UTF-8字符边界处截断,避免不完整字符""" if not text: return text try: utf8_bytes = text.encode('utf-8') except UnicodeEncodeError: return text # 从末尾向前扫描,找到最后一个完整的UTF-8字符边界 i = len(utf8_bytes) while i > 0: try: return utf8_bytes[:i].decode('utf-8') except UnicodeDecodeError: i -= 1 return "" ``` ### 3. 安全的增量计算 **处理流程**: 1. 累积tokens到缓冲区 2. 整体解码token序列 3. 应用UTF-8边界检测 4. 计算与上次安全文本的差异 5. 发送安全的新增量内容 **核心实现**: ```python def put(self, value): """TextStreamer的回调方法:累计token整体解码,避免UTF-8断裂导致的乱码""" try: # 累计tokens if isinstance(value, torch.Tensor): if value.dim() > 1: value = value.flatten() token_ids = value.tolist() if isinstance(token_ids, int): token_ids = [token_ids] self._token_buffer.extend(token_ids) else: return # 跳过无效值 # 整体解码并生成清洗后的累计 decoded_total = self.tokenizer.decode(self._token_buffer, skip_special_tokens=True) # 确保UTF-8边界完整,避免不完整字符(被截断) decoded_total = ensure_utf8_boundary(decoded_total) self._last_decoded_text = decoded_total current_round = self._extract_current_round(decoded_total) cleaned = self._post_clean(current_round) self.response_text = cleaned # 实时更新Redis中的流式结果 if self.queue_manager and self.response_text: self.queue_manager.update_stream_result(self.task_id, self.response_text) except Exception as e: logger.error(f"TextStreamer put方法错误: {e}") ``` ### 4. 乱码检测和修复机制 #### 4.1 乱码检测 正则判断特殊符号或者乱码 #### 4.2 单token修复函数 直接使用vocab.json(大模型语法表)解码token,避免tokenizer的乱码问题 #### 4.3 拉丁字符乱码修复 基于模式识别的拉丁字符乱码修复 ## 技术实现 ### 框架集成 解决方案完全兼容Transformers的TextStreamer接口,与Unsloth框架无缝集成: ```python # 创建自定义streamer custom_streamer = CustomTextStreamer(tokenizer, queue_manager, request.task_id, user_message=request.message, enable_thinking=request.enable_thinking) # 使用TextStreamer进行流式生成 outputs = model.generate( **inputs, max_new_tokens=request.max_tokens, temperature=request.temperature, top_p=request.top_p, top_k=request.top_k, do_sample=True, pad_token_id=tokenizer.eos_token_id, streamer=custom_streamer, # 使用自定义TextStreamer return_dict_in_generate=True, output_scores=False, ) ``` ## 实验结果 ### 问题解决效果 **修改前**: ``` 流式输出: "上午 + �江" 最终结果: "上午 + 珠江" ``` **修改后**: ``` 流式输出: "上午 + " → "上午 + 珠" → "上午 + 珠江" 最终结果: "上午 + 珠江" ``` ## 经验总结 ### 关键发现 通过深入分析和测试,我们发现了以下关键点: 1. **跨token编码问题**: 大部分乱码都是因为中文字符被分割成多个token导致的 - 一个中文字符通常被分割成4个token - 第一个token通常是`Ġ`(对应空格字符) - 后面3个token对应中文字符的UTF-8字节序列 2. **批量解码有效**: 使用tokenizer的批量解码功能可以自动处理跨token的编码问题 - 这是最高效的修复方法 - 能处理大部分常见情况 - 应该优先使用 3. **修复范围广泛**: 不仅限于中文字符,还包括emoji等特殊字符 - 解决方案具有通用性 - 可以处理各种多字节字符 - 适用范围广 4. **模式识别**: 乱码token通常与特定的后续token组合才能正确解码 - 需要将多个token组合起来才能正确解码 - 单独处理每个token可能无法得到正确结果 5. **拉丁字符乱码**: 发现了新的乱码模式:扩展拉丁字符与中文字符的混合 - 扩展拉丁字符位于U+00A0 - U+017F范围 - 需要基于上下文进行智能推断 - 避免硬编码,使用通用规则处理 ### 技术要点 在实现解决方案的过程中,我们掌握了以下技术要点: 1. **GPT-2映射理解**: 深入理解GPT-2的字节到Unicode映射机制 - 映射表的结构和生成方式 - 反向映射的实现方法 - 字节值的处理策略 2. **UTF-8编码原理**: 掌握UTF-8多字节字符的编码规则 - 中文字符的UTF-8编码方式 - 字节序列的组合和解码 - 错误处理机制 3. **渐进式修复**: 优先使用简单方法,复杂情况使用深度修复 - 批量解码优先 - 逐token修复作为备选 - 回退机制保证稳定性 4. **有效性验证**: 确保修复结果的正确性 - 中文字符检测 - 有效字符验证 - 质量保证机制 5. **拉丁字符乱码处理**: 掌握拉丁字符乱码的处理方法 - 正则表达式模式识别 - 上下文推断算法 - 智能替换策略 ## 兼容性测试 - **模型兼容**:适用于Qwen3及其他BPE分词器模型 - **语言支持**:支持中文、英文等多语言输出 - **框架兼容**:完全兼容Unsloth和Transformers框架 ## 适用场景 - **中文大模型推理**:特别适用于中文等多字节字符的处理 - **流式输出场景**:适用于需要实时显示生成过程的场景 - **多语言支持**:适用于需要处理多种语言的应用 - **生产环境部署**:适用于高并发、高可用的生产环境
微信小程序反编译源码后的一次偶然发现 作者: lattice 时间: 2020-04-30 分类: 网络安全 1 条评论 # 起因 一大早老爸给我发了个大佬的文章 具体的需求就是反编译小程序,拿到小程序的源码 好吧,看看就看看 ## 第一步 先贴上大佬的文章: https://www.cnblogs.com/_error/p/11726356.html 第一步我们就需要小程序的源码包 wxapkg 获取的方式非常容易,上面的文章也有写 我就把具体步骤描述出来好了 因为需要root权限获取系统文件,所以这里用到了安卓模拟器 (俺用的夜神,其他的也可) 模拟器内登陆微信并打开任意一款小程序(这里就不截图了..) 之后安装RE文件管理器,找到如下目录 `/data/data/com.tencent.mm/MicroMsg/{User}/appbrand/pkg` **{ User } 为一串16进制字符** 可能到`/data/data/com.tencent.mm/MicroMsg/`目录之后大家会不清楚具体是哪个文件夹,这里给大家举例 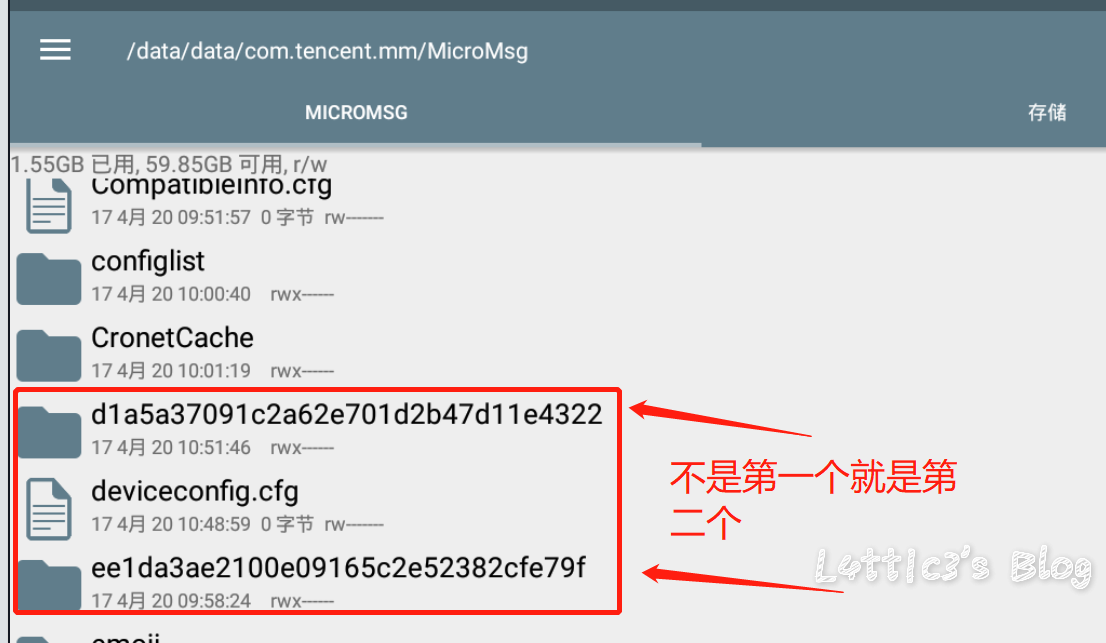 继续跟进上面的目录路径之后,就可以到达小程序的源码包目录 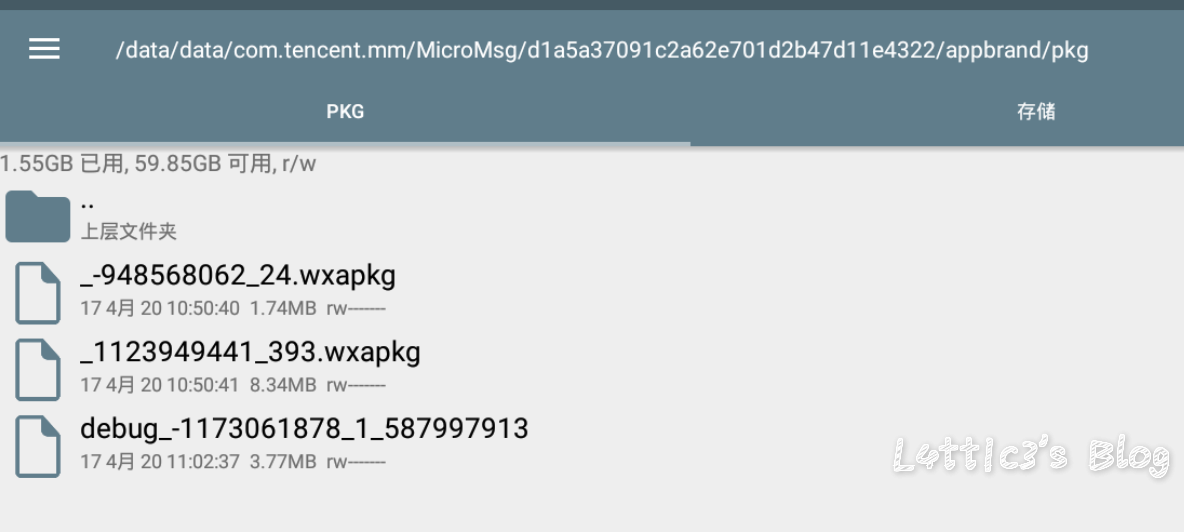 务必将你需要测试的小程序源码包打包成压缩文件 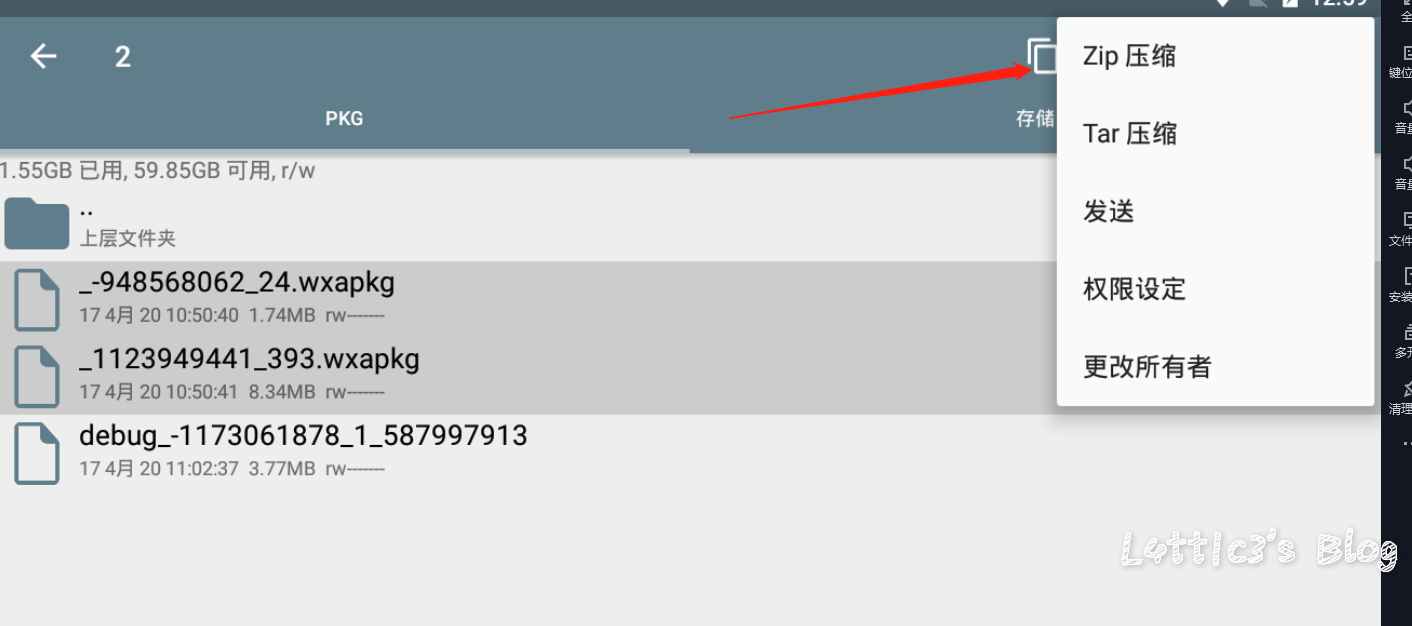 之后将此压缩文件选中,通过模拟器里的微信发到电脑就好了 这个就是我们需要反编译的小程序源码包  ## 第二步 这里需要用到工具 https://github.com/qwerty472123/wxappUnpacker/releases 下载下来,我就直接丢到linux里测试了 **注意:linux需要装好node环境(node环境安装直接百度就好了..很简单快速),同时要cd到该工具的目录下运行命令`npm install`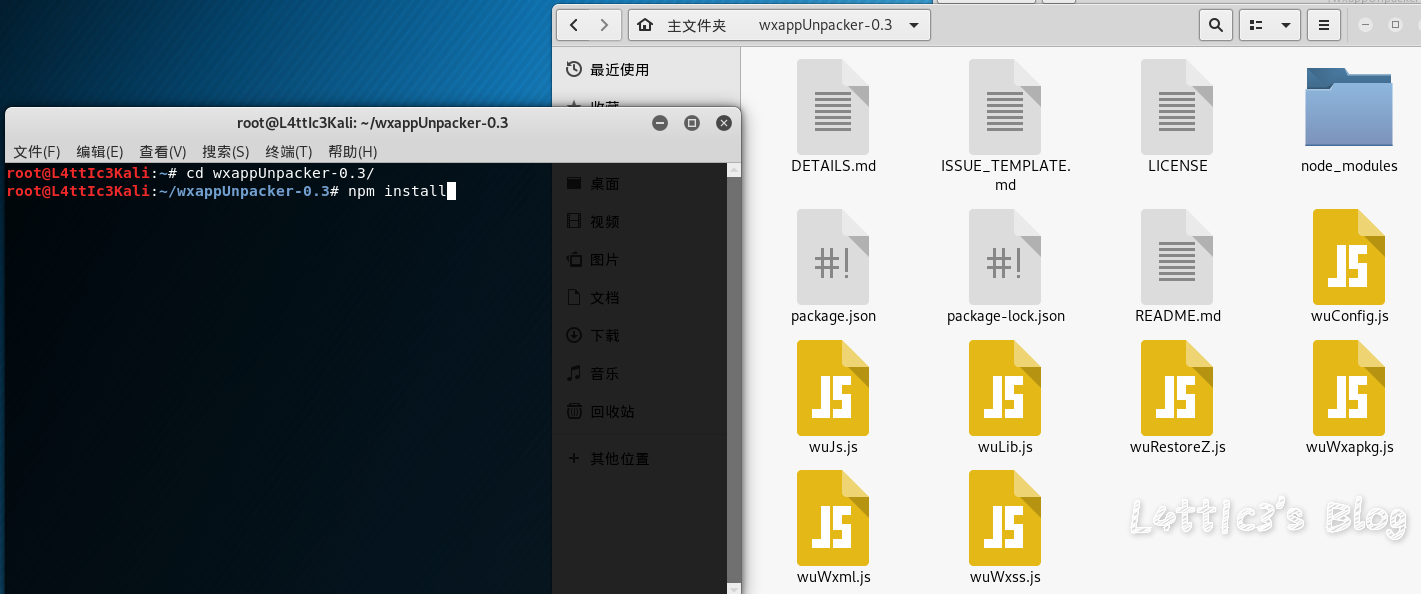** ## 第三步 所需环境和工具咱都弄好之后 开始反编译小程序,具体我们只需要用到wuWxapkg.js这个文件 **此时的操作还是需要在工具目录下** 运行命令`node wuWxapkg.js 'wxapkg包路径'` 脚本一顿操作,就会在你那个wxapkg包路径的目录下反编译出小程序的源码了 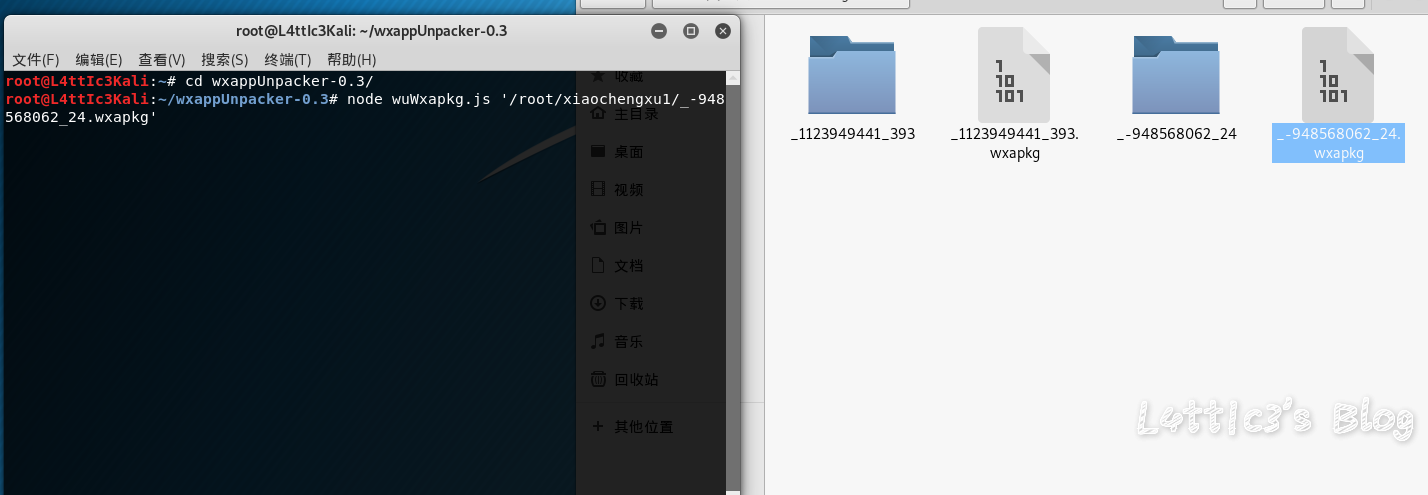 之后我就直接把这个源码丢给公司程序员去看了 # 后续 **下面的操作属于巧合导致我发现了信息泄露,不一定要像我这样用什么开发者工具,直接翻上面的小程序源码也可以找到敏感信息,下面内容只是扩展** ## 微信开发者工具 老爸要我看看源码是否可以正常显示 这里就要用到微信开发者工具了 https://developers.weixin.qq.com/miniprogram/dev/devtools/download.html 但是导入这个小程序的源码包 需要任意一个开发者的AppId 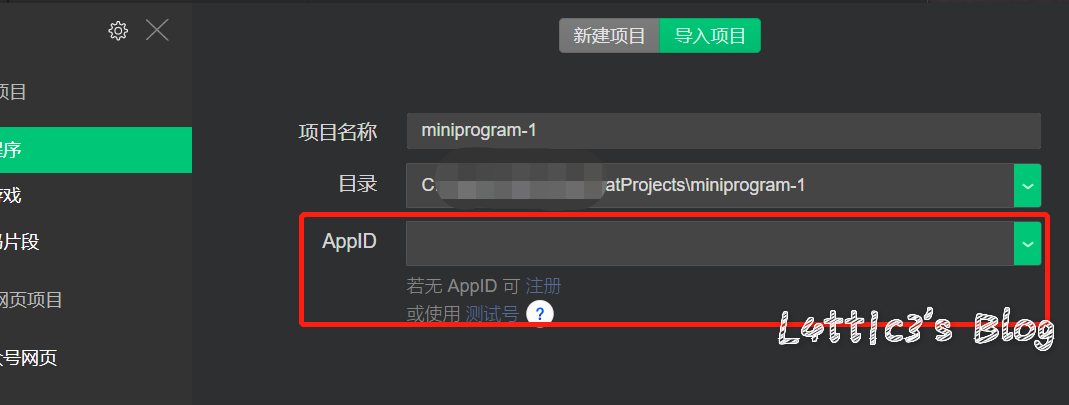 这一步还是有门槛,需要有自己的公众号来申请 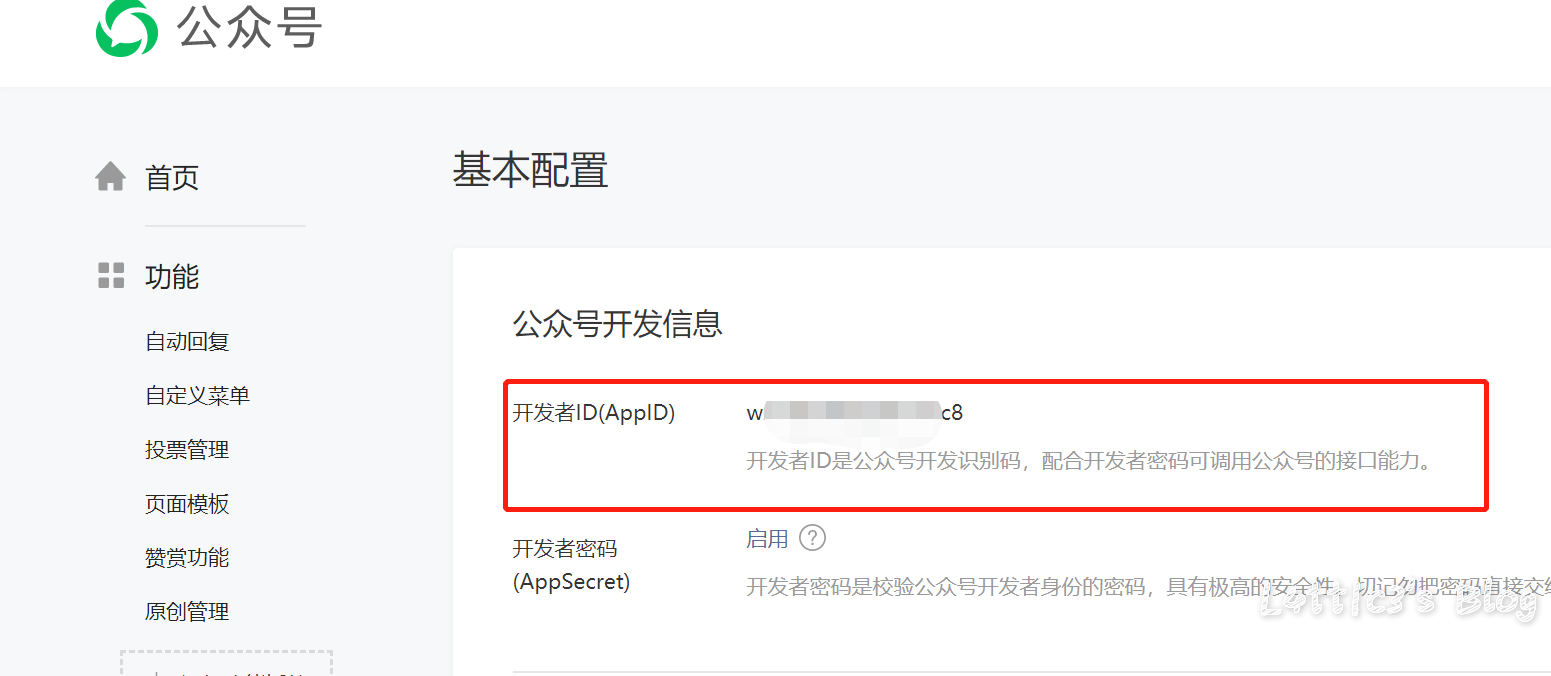 大概就是这样,填入之后导入之前反编译出来的小程序源码 ## 奇怪的请求 导入之后我发现有个`help.js`文件一直在请求`SESSION_KEY` 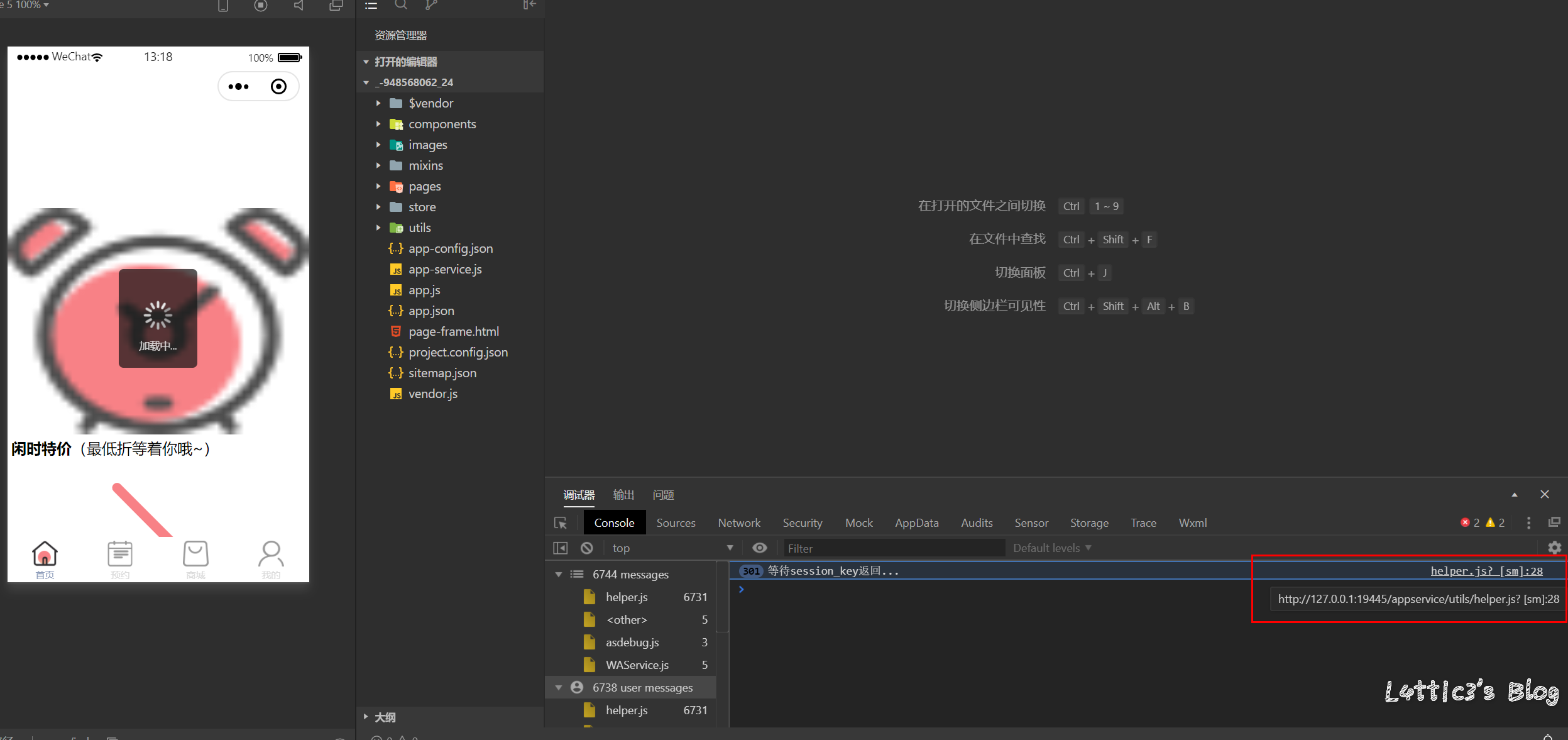 然后我直接定位到了目录里的这个js文件 发现里面都是..各种敏感信息(后台地址,支付接口id等) 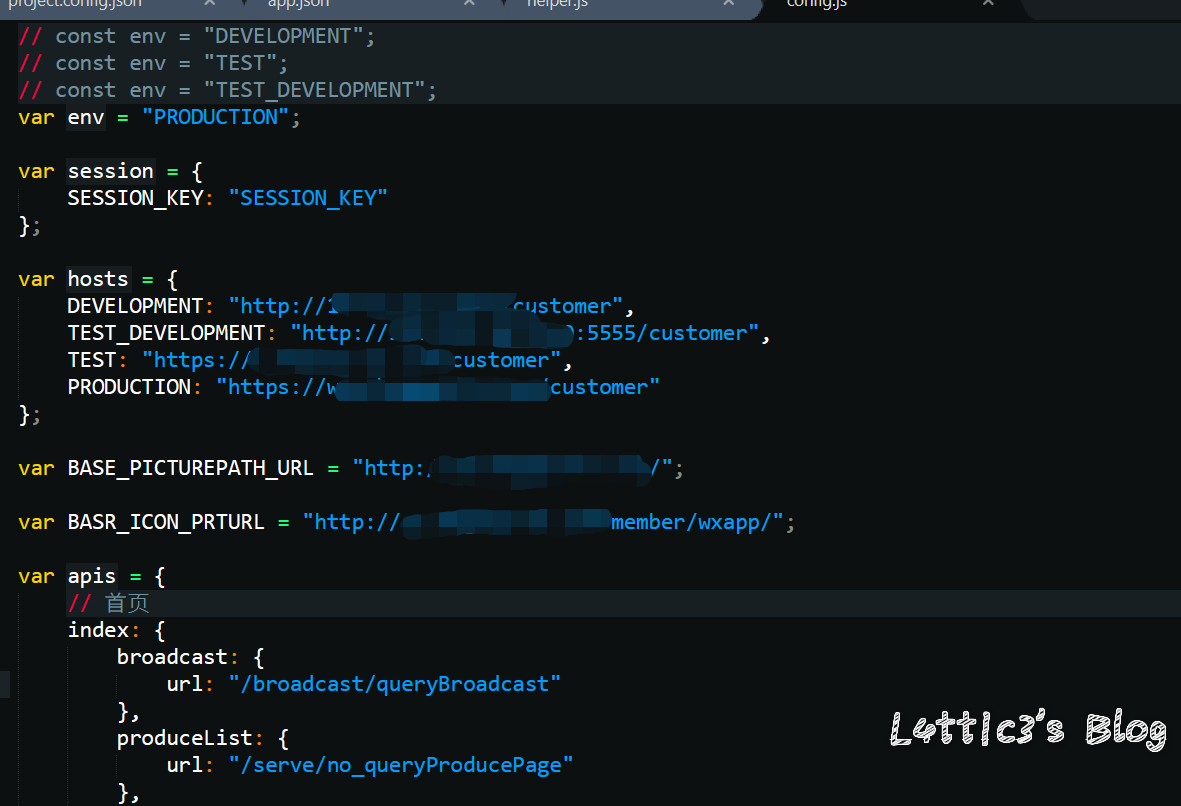 (请求的原因是他源码里没填写`SESSION_KEY`,正常发布了的小程序肯定是填写完整可以正常运行的) ## 继续深入 后面一直在翻源码的js代码看 发现小程序所有铭感信息都是写在了js文件里 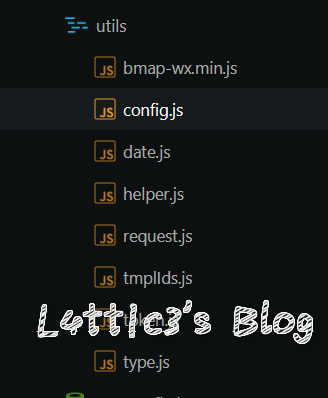 所以后期想要测试的小伙伴,目光都可以放在源码的js文件里,方便大家定位,剩下具体的就不做截图了 # 结尾 emmm其实大概也就这样吧,大家可用这个方法去测测别的小程序,看看能不能翻到一些敏感信息吧,或许对大家刷SRC也有帮助呢 XD
咪游网络CRM系统某处xss 作者: lattice 时间: 2020-01-17 分类: 网络安全 评论 在线索状态处添加线索 插入xss payload 提交保存 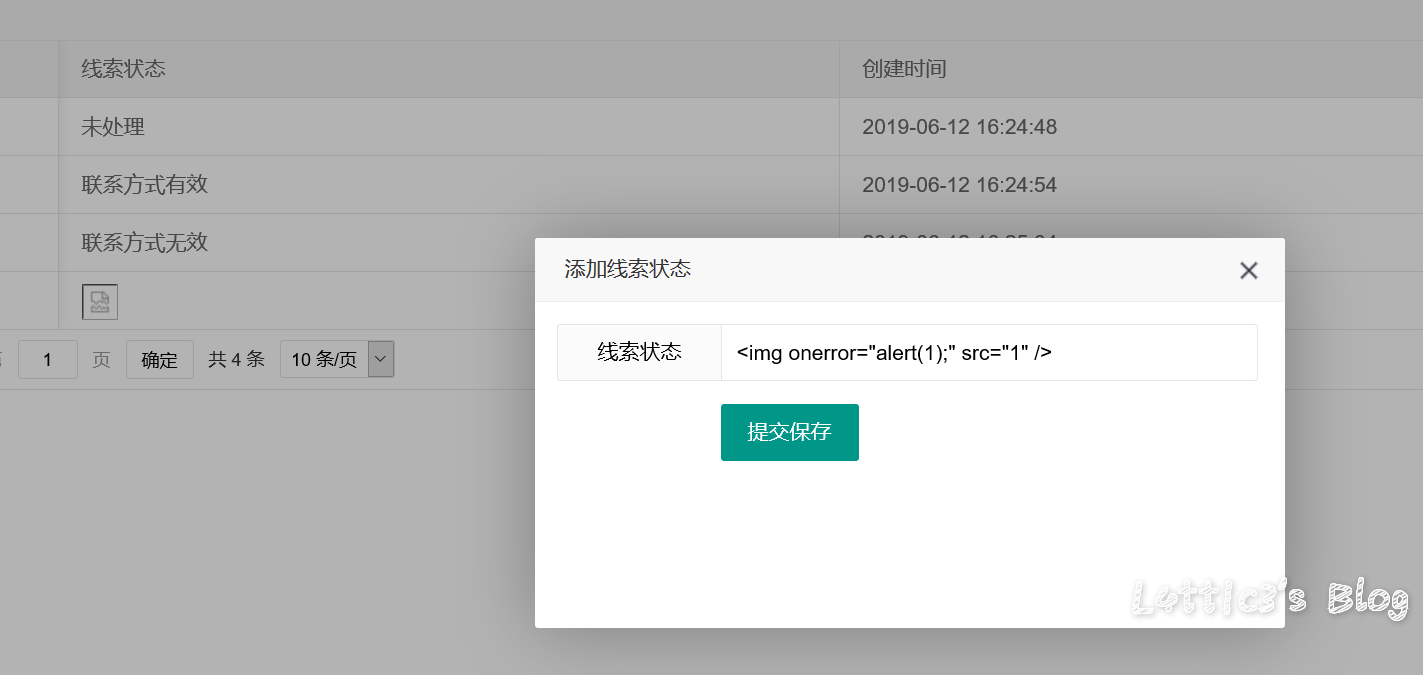 保存后刷新页面可直接弹窗 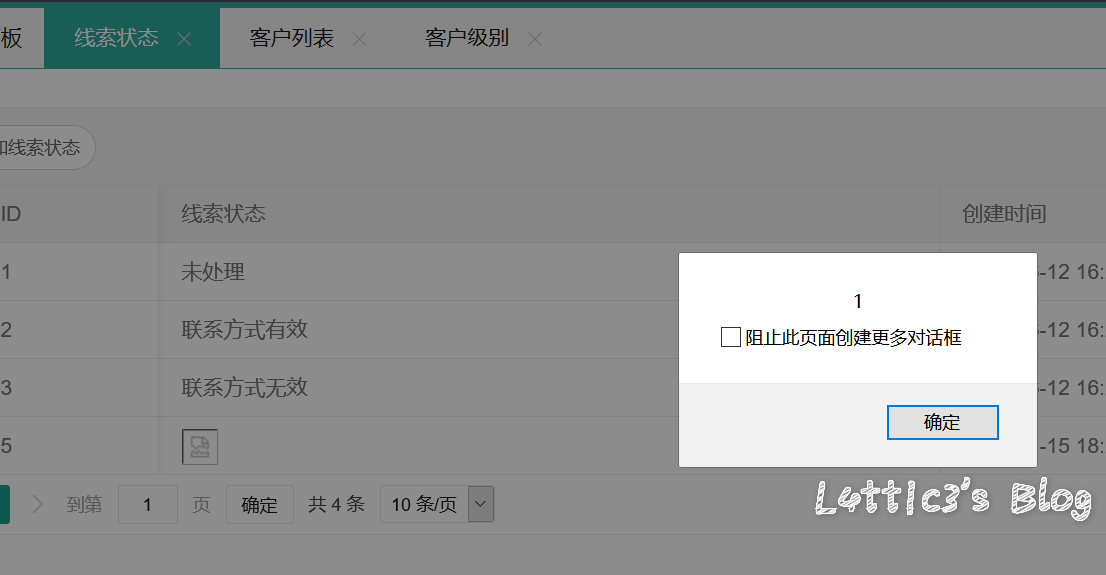 审计相关代码发现,在代码处未规避xss有关函数导致直接输出 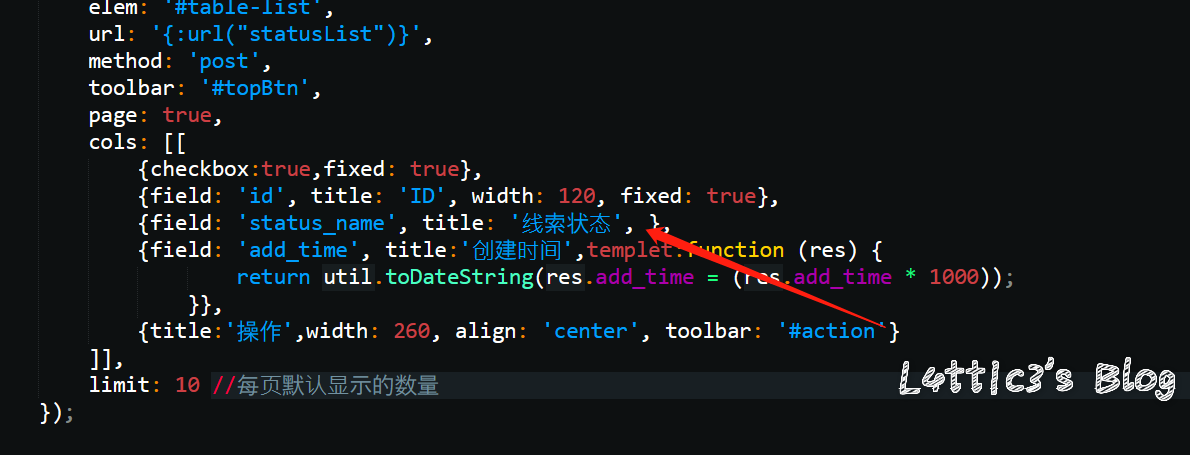 最后引发弹窗 有关文件路径:\application\admin\view\client\status_list.html
第三届强网杯决赛应急响应WriteUp(上半场) 作者: lattice 时间: 2019-09-23 分类: 网络安全 评论 # 写在开头 很有幸能进入这次强网杯的决赛并且拿到第三名的成绩 陪跑了几年线下awd的比赛了,感谢团队成员们的努力  下面是决赛上半场应急响应的WriteUp ## 事中应急响应(两道选择题) ### 第一题 网站目录下的apache文件夹里 access.log有很多post登录记录 所以判断为口令破解 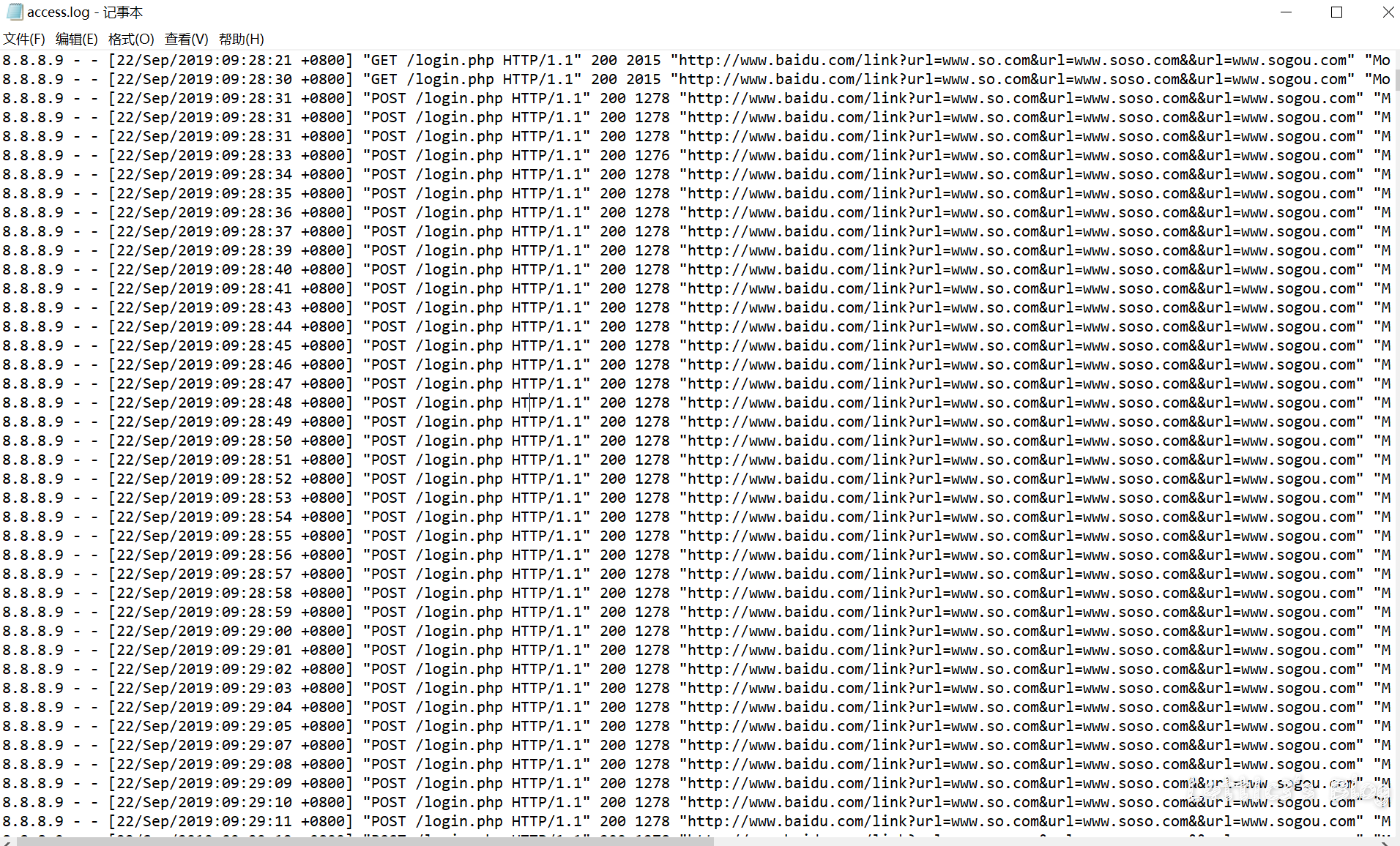 故选择 **E、口令破解攻击** ### 第二题 由于判断是暴利破解 所以可以选择ban攻击者ip 修改登录密码防止弱口令登录 安装waf或者ips等防护暴力破解导致的服务器运行故障 故选择 **C、将攻击源IP地址添加到防火墙 D、修改弱口令为强口令 E、安装WAF、IPS等防护软件或硬件 ** ## 事后应急响应(九道问答题) ### 第一题 把网站源码拖下来之后直接扫描 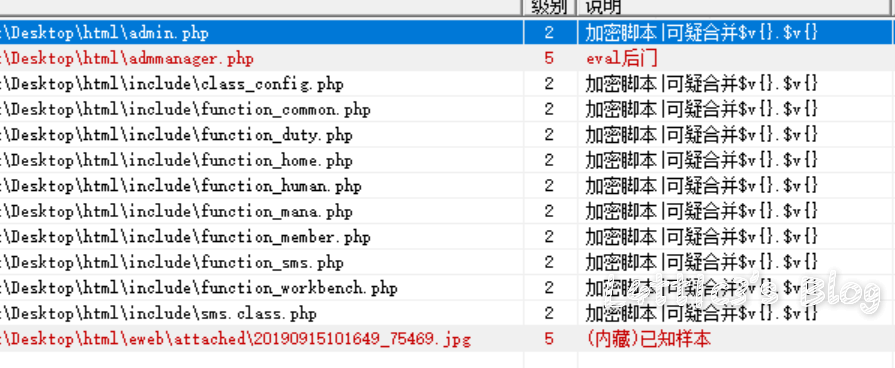 可直接得shell文件名称: **admmanager**(答案) ### 第二题 在var目录下存放了网站目录和日志目录(log) 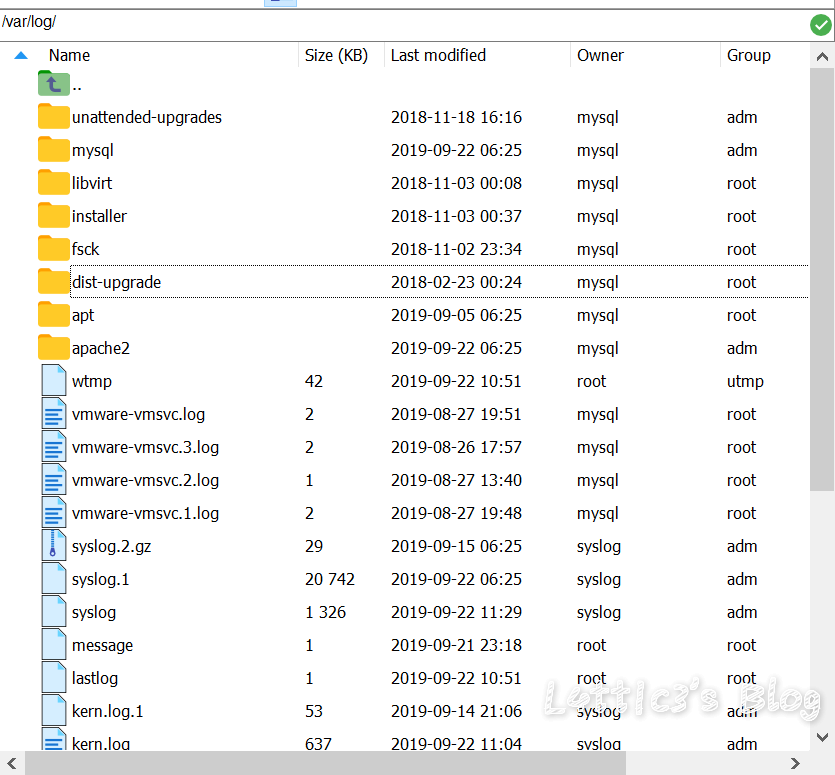 故答案为 **/var/log/** ### 第三题 使用命令 `grep "Accepted " /var/log/auth.log | awk '{print $1,$2,$3,$9,$11}'` 读log文件夹下的auth.log文件 发现有个用户名为mysq1的用户名非root用户名 所以确定为黑客登录用户名  所以可得ip地址:**172.16.5.143**(答案) ### 第四题 同上可得用户名 **mysq1**(答案) ### 第五题 同上上可得登录时间 **10:34:30**(答案) ### 第六题 输入命令:ps aux 可以发现挖矿进程  `root 1451 0.0 0.7 290052 7904 ? Sl Sep21 0:20 ./xmr-stak-cpu` 故答案为 **xmr-stak-cpu** ### 第七题 可以先发现在/etc目录下有/xmr-stak-cpu挖矿的文件夹 确定为挖矿文件价,但是挖矿需要可执行的sh结尾文件 在/bin文件夹下面发现两个sh文件(11.sh和22.sh) 在11.sh文件里发现了最终执行挖矿的文件 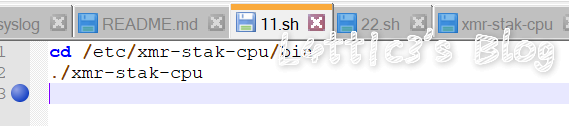 最后可直接确定绝对路径 **/etc/xmr-stak-cpu/bin/xmr-stak-cpu**(答案) ### 第八题 可以先发现在/etc目录下有/xmr-stak-cpu挖矿的文件夹下有个config.txt文件,里面有钱包地址  "wallet_address" : "fogyisland_x@hotmail.com", 故答案 **fogyisland_x@hotmail.com** ### 第九题 文件还原题...老子不会 ## 场景文件下载链接 下面提供在上方WriteUp中出现的文档以及文件 为比赛中主要的几个目录,可供下载学习 **[点这里下载哦~](https://www.latticehub.xyz/usr/uploads/2019/09/%E5%BA%94%E6%80%A5%E5%93%8D%E5%BA%94.zip)** # 总结 一个人打完上半场..最后上半场第九名 从shell响应到挖矿木马,绿盟出的题还是ok的 累了,各位晚安
关于上传点使用对象存储的套路 作者: lattice 时间: 2019-05-21 分类: 网络安全 4 条评论 操 不知道为啥今天cloudflare的cdn今天为啥这么慢 ## 开头 对象存储现在运用的越来越广泛了,现在很多厂商在上传头像、文件的位置都会运用对象存储这个功能 毕竟存储空间大又便宜并且与主机分离,相对安全 包括进行网站的备份什么的,都非常方便 像阿里云的OSS或者腾讯云的COS 可参考: https://www.latticehub.xyz/archives/124.html 下面是针对上传点使用对象存储套路的分享 (反正我也不知道算不算漏洞,有点懵的上头) ## 套路分析(可能也算不上是漏洞吧) ### 起因 **下方截图已打码处理** 上个月挖了一个网易某个站点的存储xss 首先还是先上传了构造好xss的html文件 详细可参考: https://www.latticehub.xyz/archives/120.html 上传之后数据的格式是: 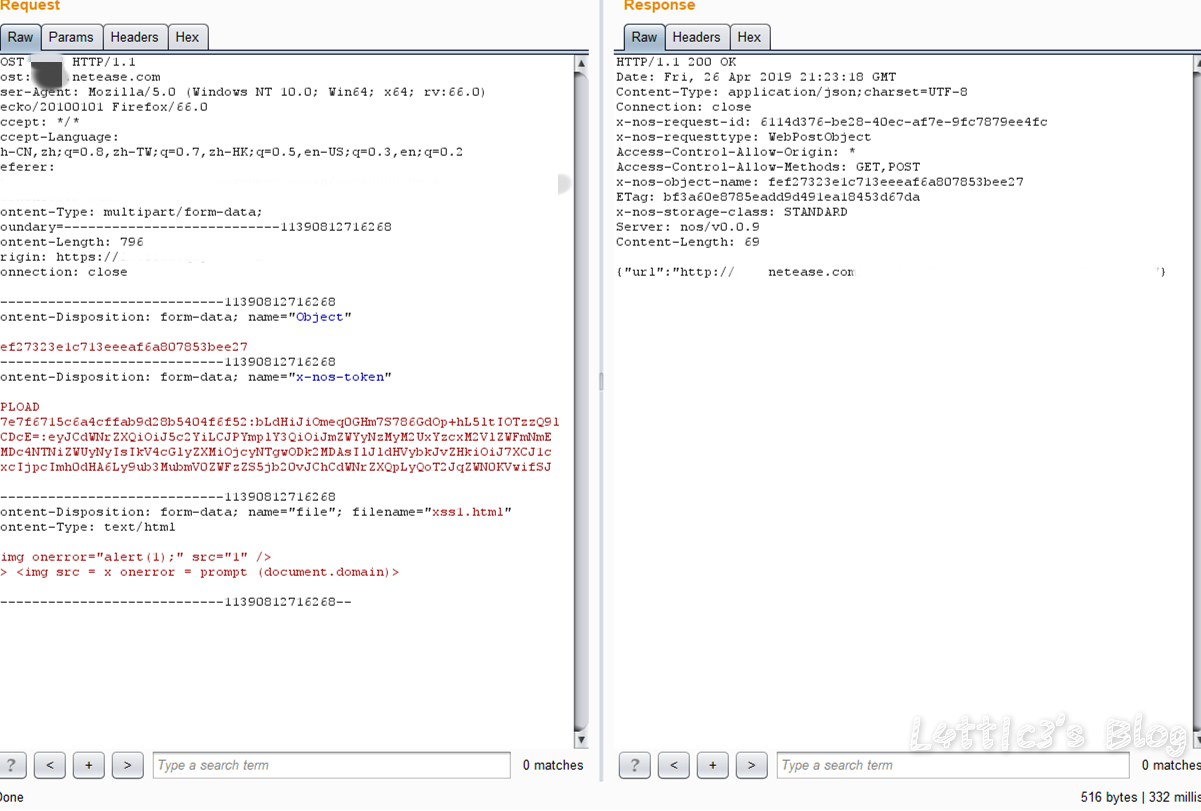 文件是在对象存储服务的网址中出现并且也出现了xss弹窗 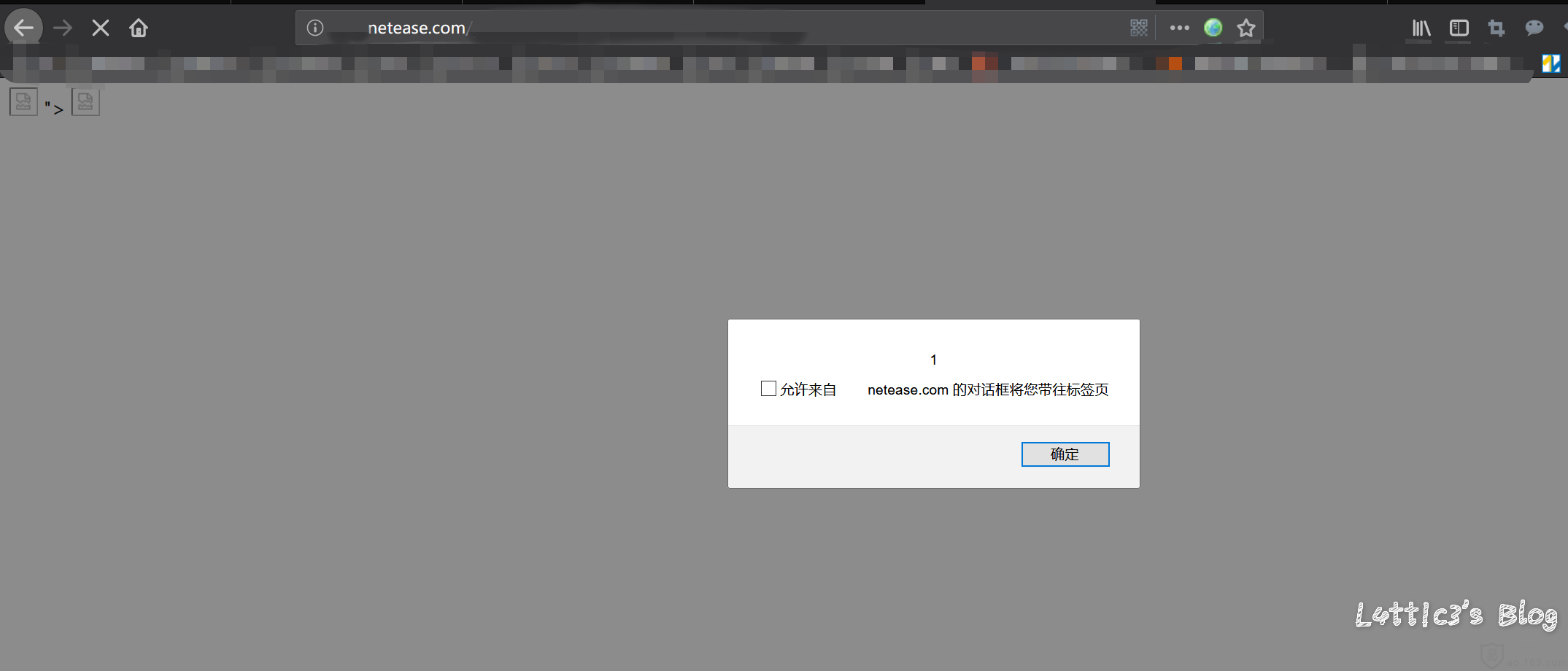 当时这个漏洞是按中危接收了(等了四天..哭了都) ### 之后嘞 之后就是...我又来到了蚂蚁金服,随便挖了一手 也是碰到了一个上传点,网站同样是使用的对象存储 上传点是上传头像的地方 所以还是老套路,构造xss的jpg文件上传改包 这时我们获取到的数据包肯定是jpg文件类型的数据包 所以在数据包的```content-type```中后面跟着的是```image/jpg``` **重点来了(敲黑板)** 然后举一反三呗...想起了上面网易的那个存储xss的数据包,然后就把数据包改成了同样的格式 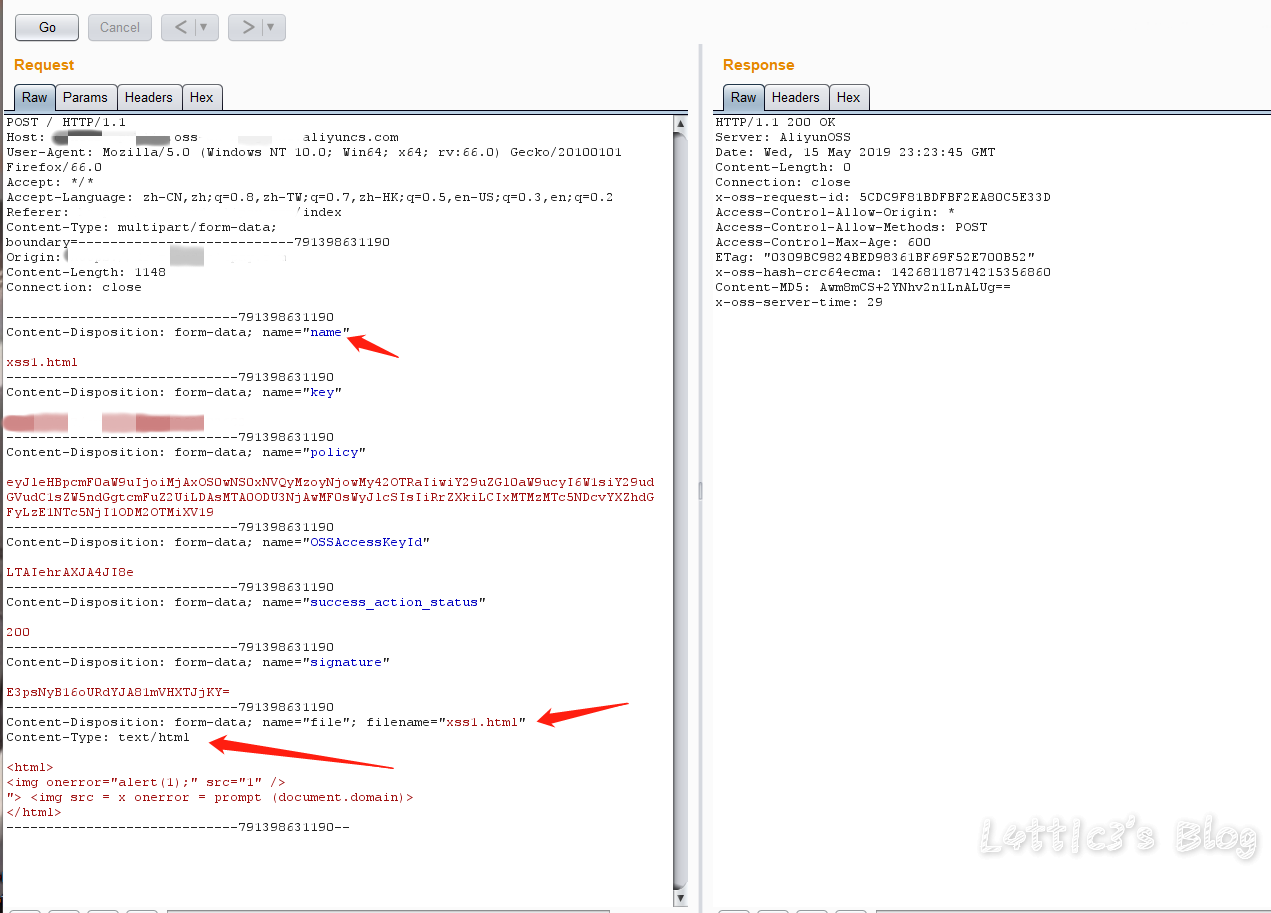 红色箭头的部分就是需要改动地方```.jpg```全部改成```.html``` 然后再将```content-type```第三个红色箭头的地方把```image/jpg```改成```text/html``` GO出去,就显示上传成功了 文件具体路径网址的构造就不多说,套路教到了,剩下的自己体会 最后也出现了弹窗  性感彩烈的提交去了 ### 结果 一波冷水直接劝退  审核的回复完全没有问题,oss服务器的确也是无法限制上传文件的类型..但是撞洞了...头疼 ## 写给提供对象存储服务的厂商的一些建议 数据提交的部分还是得做处理... 不然直接改数据格式绕过,啥文件都上传上去了,最后懂我意思吧...? ## 最后 还是那句话吧..每个src都有自己的规则,尊重各个src的审核标准以及等级评判标准,再多的东西逼逼这么多也没用..该咋样还是咋样,水费涨价,省着点口水继续挖洞吧 **在座的厂商都是爸爸,劝退可怕,告辞**